%22%20d%3D%22M425.8%2C392.9c-41.5-7.2-83.5-6.3-117.2%2C4.1l-50.5%2C25.5v-4.9h-6.9V416h-5.6%0A%09c-44.7-26.9-97.8-34.7-159.5-23.1v-28.7c0-29.4%2C23.8-53.2%2C53.2-53.2H222c14.2%2C0%2C26.3%2C8.8%2C31.2%2C21.2h6.9v13.3%0A%09c6.8-24.6%2C29.3-42.6%2C56.1-42.6h0c8.9%2C0%2C16.1-7.2%2C16.1-16.1V158.3c0-29.9%2C24.3-54.2%2C54.2-54.2h39.2V346L425.8%2C392.9z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M482.7%2C178.8H378.1c-4.4%2C0-8%2C3.6-8%2C8s3.6%2C8%2C8%2C8h39.6v188.6c-58.5-9.2-110-1-153.6%2C24.6V138.1%0A%09c42.5-27.9%2C94.1-37.1%2C153.6-27.2v45.9c0%2C4.4%2C3.6%2C8%2C8%2C8c0.8%2C0%2C1.6-0.1%2C2.3-0.3c0.7%2C0.2%2C1.5%2C0.3%2C2.3%2C0.3h43c4.4%2C0%2C8-3.6%2C8-8%0A%09s-3.6-8-8-8H469v-14.2c0-4.4-3.6-8-8-8s-8%2C3.6-8%2C8v14.2h-19.2v-44.6c0-3.9-2.7-7.2-6.5-7.9c-66.2-12.4-123.8-2.9-171.3%2C28.1%0A%09c-47.5-31-105.1-40.5-171.3-28.1c-3.8%2C0.7-6.5%2C4-6.5%2C7.9v22.4H50.3c-4.4%2C0-8%2C3.6-8%2C8v287.8c0%2C4.4%2C3.6%2C8%2C8%2C8h203.6%0A%09c0.6%2C0.1%2C1.2%2C0.2%2C1.7%2C0.2c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.6%2C0%2C1.2-0.1%2C1.7-0.2H461c4.4%2C0%2C8-3.6%2C8-8V194.8h13.8%0A%09c4.4%2C0%2C8-3.6%2C8-8S487.2%2C178.8%2C482.7%2C178.8z%20M58.3%2C142.5H78V366c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8V110.9c59.5-9.8%2C111.1-0.7%2C153.6%2C27.2V408%0A%09c-45.9-26.9-100.7-34.7-163.1-23c-4.3%2C0.8-7.2%2C5-6.4%2C9.3c0.8%2C4.3%2C5%2C7.2%2C9.3%2C6.4c52.1-9.8%2C98.4-5.2%2C137.9%2C13.6H58.3V142.5z%0A%09%20M453%2C414.4H286.4c39.5-18.8%2C85.8-23.4%2C137.9-13.6c2.3%2C0.4%2C4.8-0.2%2C6.6-1.7c1.8-1.5%2C2.9-3.8%2C2.9-6.2V194.8H453V414.4z%22%3E%3C%2Fpath%3E%0A%3Cpath%20fill%3D%22%23FCCF31%22%20class%3D%22primary-color%22%20d%3D%22M80.7%2C19.7L19.8%2C80.7V19.7H80.7z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M483.7%2C50.2c0%2C4.4-3.6%2C8-8%2C8h-15.8V74c0%2C4.4-3.6%2C8-8%2C8s-8-3.6-8-8V58.2h-15.8c-4.4%2C0-8-3.6-8-8s3.6-8%2C8-8h15.8V26.4%0A%09c0-4.4%2C3.6-8%2C8-8s8%2C3.6%2C8%2C8v15.8h15.8C480.1%2C42.2%2C483.7%2C45.8%2C483.7%2C50.2z%20M30.6%2C462.1c-5.9%2C0-10.8%2C4.8-10.8%2C10.8s4.8%2C10.8%2C10.8%2C10.8%0A%09s10.8-4.8%2C10.8-10.8S36.5%2C462.1%2C30.6%2C462.1z%20M228.4%2C26.7C213.9%2C26.7%2C202%2C38.5%2C202%2C53c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8%0A%09c0-5.7%2C4.7-10.4%2C10.4-10.4s10.4%2C4.7%2C10.4%2C10.4c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8C254.8%2C38.5%2C243%2C26.7%2C228.4%2C26.7z%22%3E%3C%2Fpath%3E%0A%3C%2Fsvg%3E) APUE
APUE这章主要讲 Unbuffered I/O,文件系统的原子操作,以及操作系统内核是如何维护相关数据结构的。
3.3 open and openat Functions
#include <fcntl.h>
int open(const char *path, int oflag, ... /* mode_t mode */ );
int openat(int fd, const char *path, int oflag, ... /* mode_t mode */ );
// Both return: file descriptor if OK, −1 on erroroflags 可以是多个 flag 用或操作组合起来。但是对于下面 5 个选项,你必须提供其中之一:
O_RDONLY: 0O_WRONLY: 1O_RDWR: 2O_EXEC: 3O_SEARCH: 4 (绝大多数系统没有实现它)
其他选项大多数是一些控制功能,比如文件不存在时创建文件(O_CREAT),再比如如果目标不是目录抛出错误(O_DIRECTORY)。有几个 SYNC 变量需要留意下:
O_SYNC:write请求会在物理 I/O 完成后,数据跟文件属性都更改后返回O_DSYNC:write请求会在写数据的物理 I/O 完成后返回,并且如果文件属性的改动不会影响到读取刚写入的数据,则不会等文件属性更新好再返回O_RSYNC:使read请求在其读取的文件区域的 pending write 做完后返回。这个选项比较特殊,各系统的实现不一样。比如 Mac OSX 没有实现这个选项,Linux 把它当作与O_SYNC等同。
其他选项,有需要时再查就好了。
openat 的含义是,在 fd 这个路径上打开 path 文件。它的应用场景在:
- 可以实现 a per-thread "current working directory"。多线程程序拥有同样的 working directory,在一个线程中更改 working directory 时会影响到其他线程。所以可以给每个线程单独分配一个目录的
fd,然后用openat函数相对于这个fd打开文件,就能实现一个线程一个“工作目录”了。(Reference) - 避免 time-of-check-to-time-of-use (TOCTTOU) 错误。书中没有详细说明,但是我发现一个 StackOverflow 问题 指出了原因。如果用
openat,打开的文件始终是相对于fd对应的目录的,无论这个目录是否被外部改名或者移动了;如果不用openat,那么有可能你检查目录权限后,这个目录被移走了,后续的文件写入就失败了。这同时可以避免一些安全问题。
3.4 creat Function
creat 函数等同于 open(path, O_WRONLY | O_CREAT | O_TRUNC, mode)。这个函数现在没什么用了,它出现的原因是一些老的系统的 open 函数没法创建函数,所以需要 creat 函数来创建文件。
3.5 close Function
调用 close 会释放纪录锁(record lock)。进程结束时,内核会把它打开的文件描述符全部关掉。
3.6 lseek Function
每个打开的文件描述符,都有一个对应的当前文件偏移(current file offset),表示 write 请求在文件的哪个位置写入。lseek 可以修改这个文件偏移值。lseek 函数会返回新的文件偏移值,所以可以用来判断文件大小(not sure whether it's best practice);失败会返回 -1,可以用来判断 fd 是不是 not seekable 的,比如 pipe, FIFO, socket 是 not seekable 的,lseek 会返回 -1 并设 errno 为 ESPIPE。
lseek 可以修改文件偏移到比当前文件大小更大的值,然后写入数据会造成空洞。空洞不会占用磁盘空间,被 read 时返回的是 0。
read 跟 write 函数都会使文件偏移值增大。
3.7 read Function
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t nbytes);
// Returns: number of bytes read, 0 if end of file, −1 on error没有太多复杂的东西。需要留意的一点是,read 读到的内容长度(也就是它的返回值)不一定等于 nbytes,比如读到文件末、或者向网络或者终端读的时候。
3.8 write Function
Nothing special.
3.9 I/O Efficiency
作者用 read 函数不同的 nbytes 值,实验了在一个 4K 对齐的文件系统内读一个大文件。结论是 nbytes 为 4096 时性能最佳。同时由于一些文件系统有一些 read-ahead 的机制来提升性能,所以 nbytes 大到了 32 字节后,性能基本上跟 4096 时差别不大。
3.10 File Sharing
这节主要讲了文件在内核中用怎样的数据结构来表示。这样可以引入不同的进程是如何读写同个文件的。
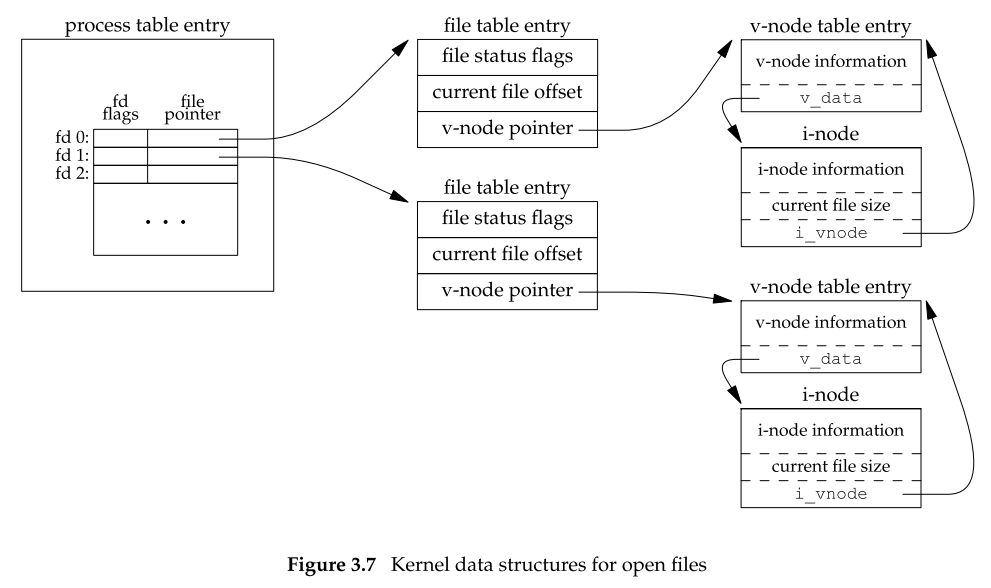
- Process table 保存 file descriptor flags,比如 close-on-exec
- File table 保存 file status flags,比如 read, write, append, sync 和 nonblocking,同时保存当前文件偏移
- v-node 是在 VFS (Virtual File System) 层引入的概念,用的是封装不同文件系统的差异;i-node 的实现文件系统相关的,但是它的数据结构在不同的文件系统间通用
这个图说明了,不同的进程是可以打开同个文件的,因为他们的 process table 和 file table 不一样。同时在一个进程内,可以有多个 fd 指向同一个文件(dup 函数,后面有讲);fork 出来的子进程拥有和父进程一样的 process table、file table。
另外,O_APPEND 选项会使每次 write 时,内核会帮你 lseek 到文件末尾再写入,同时保证这个过程是原子的,保证了多进程写同一个文件时,内容不会被写乱。
3.11 Atomic Operations
The Single UNIX Specification 提供了两个函数用来做原子读写:pread, pwrite。这两个函数可以保证 “lseek 到文件某个位置后进行读写操作” 这个过程是原子的,并且调用完后不会修改 current file offset。
另外一个涉及原子操作的场景,是在创建文件时。为 open 同时指定 O_CREAT 和 O_EXCL 时,如果文件已存在会报错。但是这种情况下,“判断文件是否已经存在”和“创建文件”这两个过程是一起(atomic)被执行的。如果你想实现“文件不存在时则创建它”,那么你应该用这两个参数。
3.12 dup and dup2 Function
#include <unistd.h>
int dup(int fd);
int dup2(int fd, int fd2);
// Both return: new file descriptor if OK, −1 on error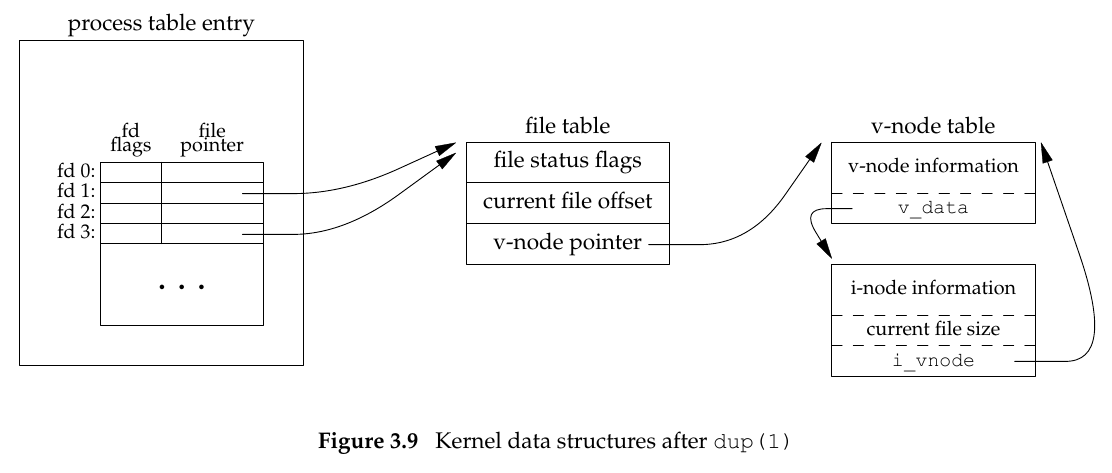
这两个函数,可以复制出一个新的 fd,指向一样的 file table。区别在于,新的 fd 的 FD_CLOEXEC 会被清掉(dup2 只在 fd 不等于 fd2 时清掉)。
对于 dup2,如果 fd2 已经存在并且不等于 fd,则会先被 close() 掉;如果相等,则什么都不做就返回 fd 值。
dup(fd) 等价于 fcntl(fd, F_DUPFD, 0);dup2(fd, fd2) 近似等价于 close(fd2); fcntl(fd, F_DUPFD, fd2),区别在于 dup2 是原子的,并不会把 close() 和 fcntl() 拆开做,同时有一些 errno 不一样。
3.13 sync, fsync, and fdatasync Functions
大部分 UNIX 系统内核提供了 buffer cache 机制。buffer cache 是一块存在在内存中,并且不会被换出的缓存。它用来作为硬盘或者其它低速设备的内容缓存。比如你对硬盘的写入,可能会被缓存起来而不是马上写入硬盘,同时操作系统有可能把小的写入操作组合成大的操作;同时你读取的文件内容如果在 buffer cache 中,那么内核可以直接给你而不需要读硬盘。据说 buffer cache 可以减少 85% 的磁盘 IO。
调用 sync 会告诉系统,尽快把 buffer cache 里的改动写到磁盘里,但是它不等数据写完后返回,而是马上返回,所以没什么卵用(参考 这个回答 的评论)。fsync 和 fdatasync 是针对某个 fd 的,它会等到 buffer cache 中的数据写完再返回;区别在于 fdatasync 不会等文件的属性被更新再返回。
3.14 fcntl Function
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* int arg */ );
// Returns: depends on cmd if OK (see following), −1 on error五个功能:
- Duplicate an existing descriptor (cmd = F_DUPFD or F_DUPFD_CLOEXEC)
- Get/set file descriptor flags (cmd = F_GETFD or F_SETFD)
- Get/set file status flags (cmd = F_GETFL or F_SETFL)
- Get/set asynchronous I/O ownership (cmd = F_GETOWN or F_SETOWN)
- Get/set record locks (cmd = F_GETLK, F_SETLK, or F_SETLKW)
其中第四、五项暂时没有细讲,只说了前三个。
如果要判断某个 fd 以什么访问模式打开,需要用 F_GETFL 的结果与 O_ACCMODE 做与运算,再看结果是 O_RDONLY 还是 O_WRONLY, O_RDWR。原因很简单。
留意使用 F_SETFL 前要先 Get 出来,避免把已有的 flag 给干掉了。
书中给出了一个使用 fcntl 的场景,比如你的程序读的是标准输入进行,但是提供把标准输入重定向到文件的,又是 shell 做的。所以你没有机会在 open() 时指定 flag(是 shell 打开的文件)。这时候你可以用 fcntl 改变文件 flag。
文中又对 O_SYNC 做了实验,显示 Linux 下使用 fcntl 设置 O_SYNC 是无效的。然后使用 O_SYNC / fsync / fdatasync 这些方式写文件,消耗的时间跟系统实现很相关,并不如你预测的那样。
3.15 ioctl Function
这些函数主要是 Terminal I/O 在用,不需要怎么关注。
3.16 /dev/fd
主要用在命令行上,/dev/fd/0 表示标准输入,/dev/fd/1 表示标准输出等等,如:
$ filter file2 | cat file1 /dev/fd/0 file3 | lpr在大部分系统中,程序中 open("/dev/fd/13", mode) 相当于 dup(13),mode 参数被忽略;但是 Linux 的实现机制不太一样,它的 /dev/fd/n 是个软链接到具体文件,所以 mode 还是生效的。