Bloom Filter(布隆过滤器)是一种概率数据结构(probabilistic data structure)。它被用来判断一个元素是否存在一个集合中;但它可能会有 false positive,即元素不存在、但仍然报存在。False positive 的概率可以调校得很小。应用时需要考虑场景能否容忍 false positives。
一些使用场景:
- 注册新用户时判断用户名是否已被占用(能容忍一定程度的误报)
- Medium 在做推荐时,用它来判断用户是否看过文章
- Chrome 用它来判断是否恶意 URL
它仅支持两个操作:
- insert(x):插入一个数据到 bloom filter 中
- lookup(x):查找一个数据是否在 bloom filter 中,但是有一定概率报 false positive
原理
开一个长度为 n 的 bit vector。选几个 hash function。每当有新数据被添加进来时,将其 hash 值运算出来再对 n 取余。将 bit vector 中相应的 bit 置为 1。比如:
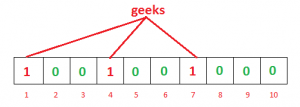
表示:
hash1("geeks") % 10 == 1hash2("geeks") % 10 == 4hash3("geeks") % 10 == 7
同样的,"nerd" 加进来后:
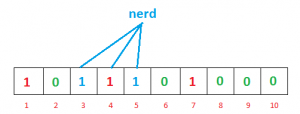
进行搜索时,也对搜索的 key 做如上相应的几次 hash 运算。比如查 "cats",如果得出的结果分别是 (3, 5, 7),bit vector 中这几个位置都是 1,因此 bloom filter 会认为 "cats" 存在,引起 false positive;如果得出的结果是 (3, 5, 6),由于 bit vector 中 6 的位置为 0,那么 "cats" 一定没有被加入进来过。
避免 false positive 的方法在于增大 bit vector 的位数。
因为可能存在不同的元素 hash 出来的三元组一致,因此 bloom filter 无法支持删除元素。
如何选择哈希函数
几个哈希函数间应该是 互相独立的,且哈希结果应该是 离散型均匀分布的(discrete uniform distribution)。而且它应该足够快,因此 密码学中的哈希算法并不是很合适(性能差一些)。
常用的有 murmur、fnv 及 HashMix 等。没有深入。
Scalable Bloom Filter
Redis 实现了 scalable bloom filter。
Redis 在初始化 bloom filter 时可以指定容纳元素的 capacity 以及 expansion rate:
BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]比如 capacity 设为 1000,EXPANSION 保持默认的 2,那么:
- 假设初始的 bit array 长度为 n(不可在命令中设置,暂时没有了解它的值是什么)
- 不停添加元素,当添加到 1000 个(capacity)时,
- Redis 自动扩容,会新建一个 2n 长(视 expansion)的 bit array;老的 bit array 仍然保留
由于 bloom filter 没有保留元素的初始值,因此扩容过程并没有类似 hash table 的 rehashing 过程。扩容之后会有多个 bit array,因此:
- 新增元素时,只会插入最新的 bit array,避免老的 bit array 过于饱和而增加 false positive 的概率
- 搜索元素时,会搜索全部的 bit array,如果有任一匹配,则返回存在