数据库事务。内容主要来自 Designing Data-intensive Applications 第七章。
数据系统中,有很多种异常情况:
- 数据库软件或者硬件 可能随时会出错(包括正在写操作的过程中)
- 应用程序 可能随时会崩溃(包括正在执行一系列的数据库操作)
- 网络问题 可能会切断应用程序与数据库间的连接,或者切断不同数据库节点中的连接
- 多个客户端 可能同时向数据库写入,覆盖彼此的数据
- 一个客户端可能读到 更新了一半的无意义的数据
- 多个客户端之间的 竞争条件(race condition)可能导致 bug
为了简化对上述情况的处理,事务(transaction)的概念被发明出来。事务表示把一组读写操作组合成一个逻辑单元,它们要么一起成功(被提交),要么一起失败(中断、回滚)。如果失败了,应用程序可以安全地重试。事务是重点在于 没有部分失败(partial failure)。
事务并不是天然存在的,而是人们为了简化问题提出的概念。事务有好处也有代价(cost)。有些时候数据系统可以不需要事务(比如为了高性能或高可用性),事务提供的安全能力也有其他办法提供。
The Slippery Concept of a Transaction
大部分数据库的事务机制,设计上都源泉于 1975 年推出的 IBM System R。2000s 开始,NoSQL 数据库开始流行,但部分 NoSQL 没有或者仅支持较弱的事务机制。
有一种常见的误解是:事务会影响数据库的高性能和高可用性。这并不完全正确,而应该视不同场景做选择。
The Meaning of ACID
事务机制提供的安全保障能力,被称为 ACID,即「atomicity, consistency, isolation and durability」。虽然很多数据库称自己为 ACID-compliant,但不同数据库之间对 ACID 的理解和实现可能不一样。
Atomicity
原子性(atomicity)表示一个事务中,当客户端发起多个写请求时,如果过程中有失败,数据库应该撤回这过程的任何修改。
Consistency
一致性(consistency)指数据保持正确。比如一次转账中,转出的金额和收到的金额应该是一致的。一致性是应用程序在原子性、隔离性和持久性的帮助下,达成的一个目标。它是应用程序本身的目标,而不是数据库系统的。
Isolation
隔离性(isolation)表示当数据库执行多个并行的事务时,它们之间是相互隔离的。它被用于并行控制。如果没有隔离,可能导致多个事务同时读写一批数据而出现的各种问题。
Durability
持久性(durability)表示写入一旦事务成功提交,则写入的数据不会丢失。
对于单节点数据库,持久性一般表示数据已经落盘(或者非常早期的磁带,或者复制到备机)。对于多节点,一般表示数据已经成功复制到若干节点。
但持久性不是无限制的。如果你的硬盘和全部备份都坏了,那数据库系统也无能为力。数据甚至会慢慢损坏,比如 SSD 或者磁盘中的数据都有概率会自然损坏。
Single-Object and Multi-Object Operations
ACID 针对的是 写多个 object(rows, documents, records)的场景。
Multi-object transaction 的场景中,数据库 需要一种机制来确定一组读写操作是属于同个事务的。一般是 基于客户端的 TCP 连接 来判断,在请求中的 BEGIN TRANSACTION 和 COMMIT / ROLLBACK 之间的语句即属于同个事务。(但实际实现上可能稍微更复杂一点,比如要处理客户端 COMMIT 之后还没收到回复网络就断开的情况。)
很多非关系型数据库不提供写多个 object 的机制。它们可能支持批量写(multi-put)操作,但并不表示这一组写是原子的,有可能一批 key 成功了,另外一批失败了。
Single-object writes
对于单个 object 的情况,一般数据库存储引擎保证了写数据时的原子性(比如通过 WAL)。而隔离性则经常通过对单 object 上锁来实现,即同时只允许一个线程写。
为了避免多个 read-modify-write 过程带来的问题,主流的解决方法是:
- 提供一些原子操作的能力,比如 Redis 的 INCR 可以原子地增加某一 key 的值
- 提供 compare-and-set 操作,后面详谈
上述的手段都不属于事务的范畴,也跟 ACID 不沾边。
The need for multi-object transactions
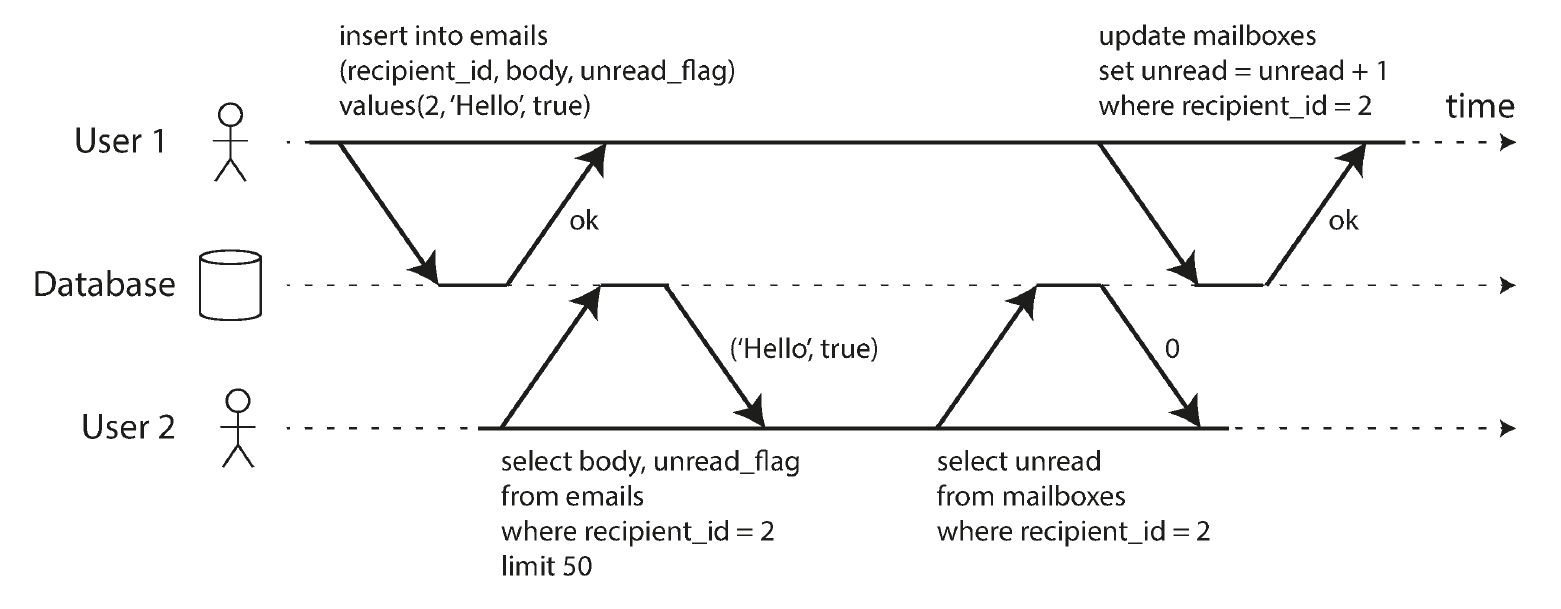
为什么需要事务能力,这是显而易见的。但有一个场景是 denormalization。比如有一个邮件应用,可以显示每个人的邮件列表和未读邮件数。但当邮件列表的数据库表太大时,计算未读邮件数就非常耗时,因此做 denorm,把未读数量单独放到一张表中维护。这种场景对 ACID 能力有依赖。
另外像非关系型数据库,由于缺乏 JOIN 能力,也提倡做 denormalization,因此也需要事务机制来保证数据的一致性。
Handling errors and aborts
- Note
- 这段内容对开发应用程序有帮助,应该仔细理解这其中的细节,考虑到不同场景的错误应该分别如何处理。
ACID 意味着当一个事务失败时,你可以安全地重试它。但有一些场景需要思考:
- 如果事务实际上成功了,但是网络问题(比如 TCP 断连)导致客户端并不知道最终的 COMMIT 有无成功,那客户端的重试可能会引起重复数据。这种情况需要应用程序级别的 dedup 逻辑。好的实践是,在插入数据的地方生成唯一 ID 并加上唯一索引,这样第二次插入数据时会报错,避免重复插入数据
- 如果出错是因为系统过载,那重试可能会加剧问题。可以限制重试次数或者使用指数级增长的重试间隔(exponential backoff)
- 对于暂时性的错误(如系统过载、网络异常等),重试是有意义的;但如果是永久性的错误,比如违反了唯一性约束,那重试没有意义
- 如果数据库事务只是一套连续操作的一部分(存在 side effect),比如提交数据库前发了邮件,那要注意重试时避开 side effect。二阶段提交(two-phase commit, 2PC)对这种场景有所帮助
Weak Isolation Levels
并发问题(竞争条件)出现在两个事务操作同一块数据时,比如一个事务读取了另外一个事务正在修改的数据,或者两个事务同时修改同一块数据。并发问题非常难定位,不是必现,而且在大型应用中可能有很多处代码访问了数据库。因此数据库提供了 事务隔离(transaction isolation)来避免并发问题。隔离的最终目的是实现 可串行化隔离(serializable isolation),即数据库使得每个事务都像是串行做修改。但由于可串行化隔离带来的性能影响,实际上数据库提供了多个相对弱的隔离级别,以应对不同的使用场景。
Read Committed
最基础的隔离级别是 读已提交(read committed),它保证:
- No dirty reads:向数据库读数据时,只会看到已经提交的数据
- No dirty writes:向数据库写数据时,只能覆盖已提交的数据(即两个事务不能同时修改同一个数据)
No dirty reads
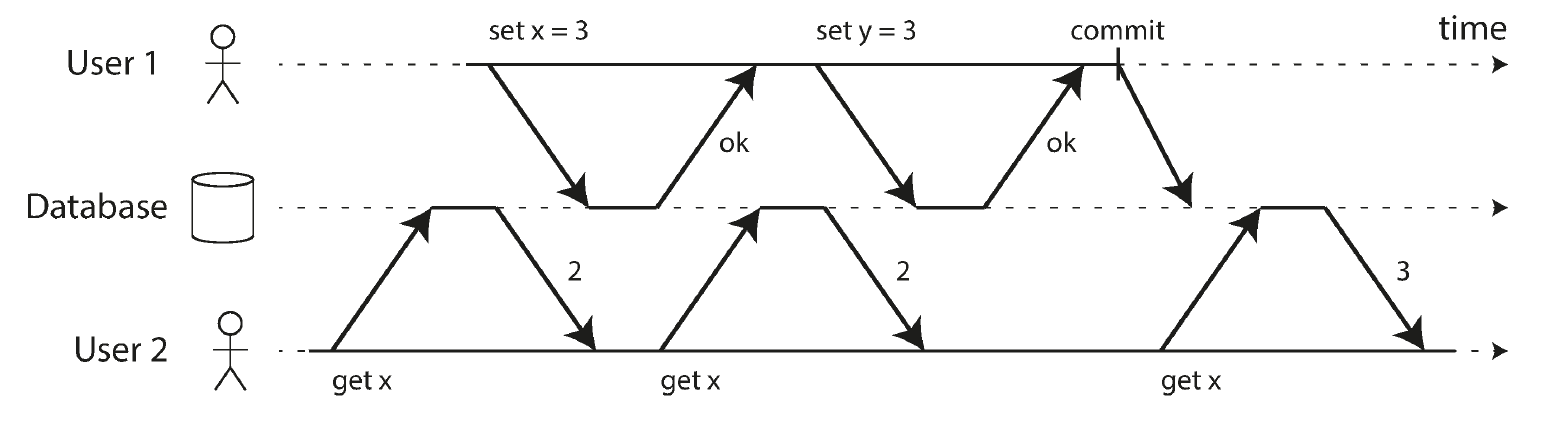
No dirty reads 的中,当 user 1 的事务未提交时,user 2 查询的 x 值就永远是 2。
No dirty reads 存在的意义很明显,比如你并不想看到别人修改一半的数据,因为会导致应用层面的数据不一致(比如转账中一方已扣款,另外一方未收到款);也可能其中修改了数据后又回滚了。
No dirty writes
No dirty writes 是为了防止数据被多个事务同时覆盖,比如下面这个例子:

某商品同时被 Alice 和 Bob 拍下,结果因为 dirty writes 导致收货人是 Alice 但买家却是 Bob,引起了数据不一致。
避免 dirty writes 的方法是,当有一个事务对数据做出修改但未提交或回滚时,其他事务无法修改该数据的值,需要等待前者完成。
Implementing read committed
实现读已提交最简单的做法是使用 行锁(row-level locks)。当一个事务想修改某一行时,它需要先获得这一行的锁,直至事务提交或回滚。它持有这个锁的过程中,其他事务无法获得这个锁,因此也无法修改数据,这就避免了 dirty writes。对于 dirty reads,也可以采用类似的方法获得一个锁,但是在读完后马上释放这个锁。
但实际上 这种方式性能很差。假如有一个执行时间很长的事务存在,把某一行锁了很久,那这个过程中读请求都需要等待,这对于大型在线应用是不可接受的。实际上数据库会纪录被修改的行的原来的值,一旦写操作的事务未提交,读此数据时,会直接返回原值。但主流数据库中也只有 IBM DB2 和 Microsoft SQL Server 还用锁来实现,其他的大多基于下文提到的快照方式。
- Note
- 有些数据库(比如 MySQL)还提供 read uncommitted 级别。它的隔离性比 read committed 更弱,只防止 dirty writes,不防止 dirty reads。
Snapshot Isolation and Repeatable Read
Read committed 看似一个已经不错的隔离等级了,但实际上它 会造成某段时间内应用数据的不一致。这种情况称为 不可重复读(nonrepeatable read)或 读偏(read skew),比如下面这个例子:
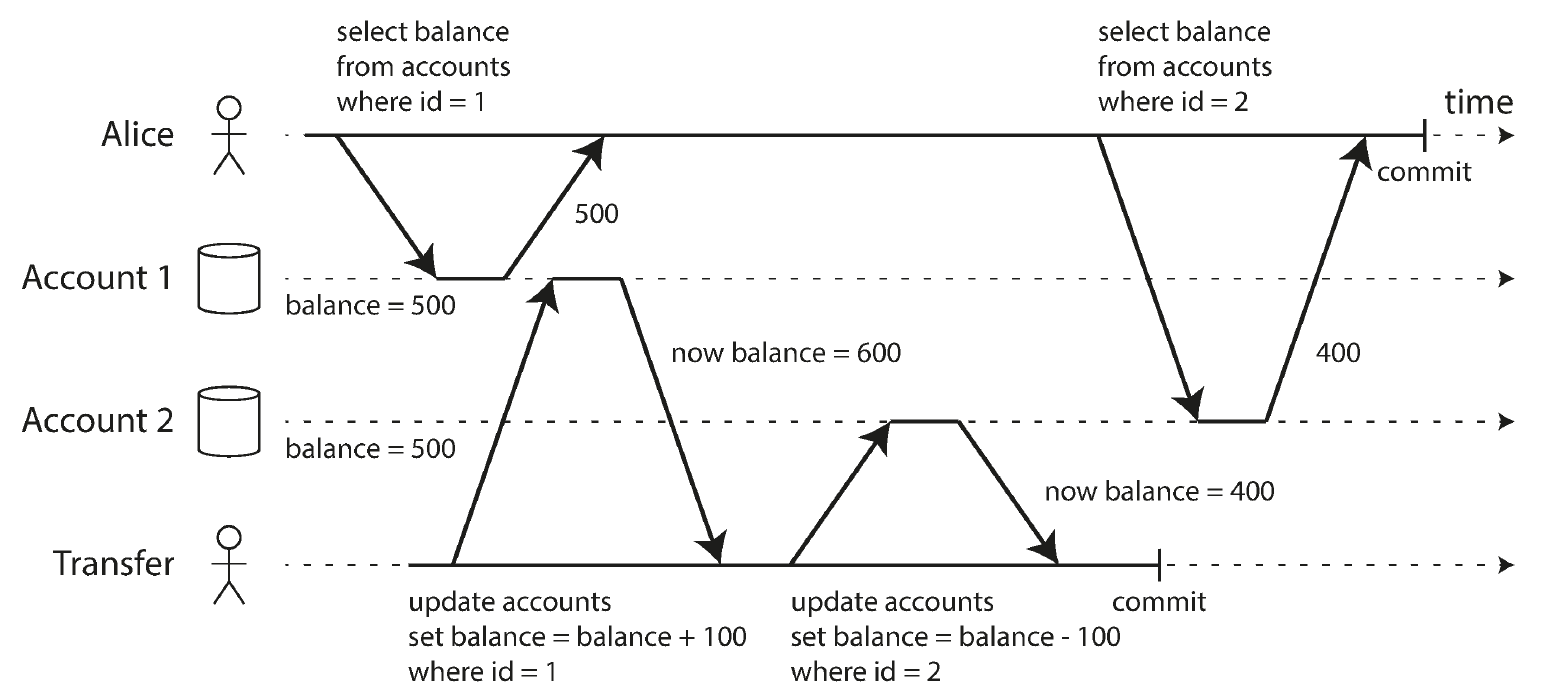
Alice 有两个账户,分别有 500 元,帐户 2 向帐户 1 转 100 元。但 Alice 在上面的场景下,可能看到账户 1 有 500 元,账户 2 只有 400 元,而有 100 元消失不见。虽然随后她刷新数据会看到账户 1 已经变为 600 元,但这仍然是不可接受的。
有些场景也 无法容忍这种暂时的不一致,如:
- 备份数据:耗时很长,这个过程可能有很多不一致的数据被读取及纪录
- 分析数据或做数据完整性校验
快照隔离(snapshot isolation)是解决这种问题的方法。在读已提交的基础上,当一个事务中读取数据时,只会读到这个事务开始时的数据库的快照;而任何进行中的其他事务做的修改,都不会被读取到。
快照隔离是主流关系型数据库的默认隔离级别。
Implementing snapshot isolation
在快照隔离的实现上,也同读已提交一样使用了写锁来防止 dirty writes。快照隔离暗含着 读不会阻塞写,写也不会阻塞读,所以读的过程中不用锁,而是保存了数据在不同过程中的值。这种技术被称作 多版本并发控制(multi-version concurrency control,MVCC)。对于读已提交,数据库需要纪录某个数据的 已提交版本 和 已覆盖但未提交 版本,对比快照隔离仅在于数据的版本数少了;因此 很多数据库也在读已提交级别中使用一样的 MVCC 技术。
快照隔离的重点在于,按时间顺序赋予每一个事务一个增长的 ID,并纪录下对数据的修改:
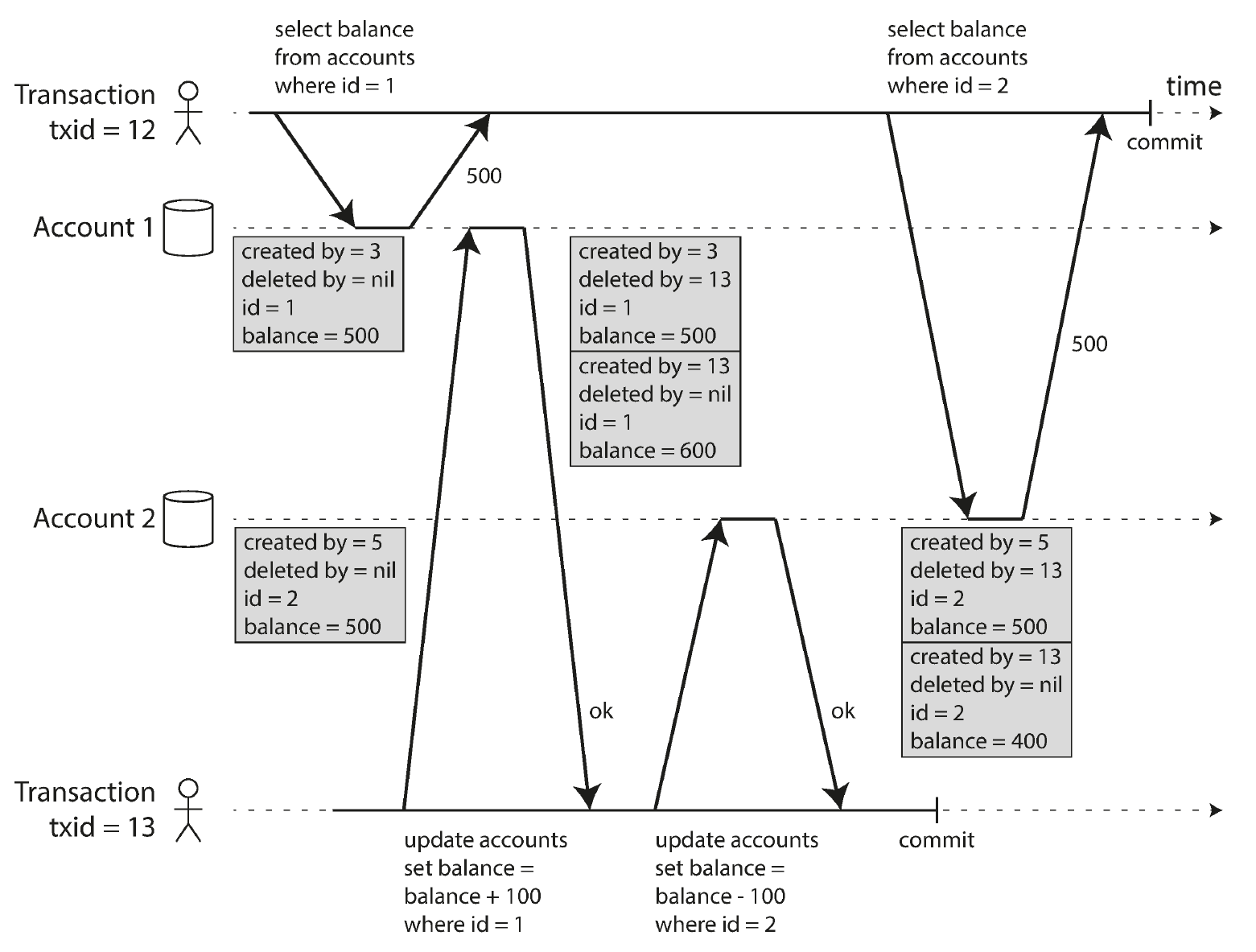
当事务新增或者删除数据时,会各有一条带着事务 ID 和 created by / delete by 以及具体值的纪录。修改数据时,则会产生一条 created by 和一条 deleted by 共两条纪录。
控制好这些纪录的 可见规则 后,即可实现快照隔离。即对当前事务而言:
- 在它开始时,数据库判断当前还有哪些事务在被处理,这些事务的修改不可见
- 更迟开始的事务(事务 ID 更大),它的修改不可见
数据库系统可以 定期做垃圾回收,回收被标记为 deleted 的行、不再需要被使用的 created by / deleted by 纪录。
Indexes and snapshot isolation
索引在有多版本能力的数据库中怎样实现?
一种方法是把索引指向该行的全部版本,再根据当前事务的情况做过滤。
另外一种流行的方法是使用 append-only / copy-on-write 技术。未深究。
Repeatable read and naming confusion
对于快照隔离,不同的数据库系统中叫法不一样。Oracle 叫作 serializable。PostgreSQL 和 MySQL 叫它 repeatable read。SQL 标准在这块带有岐义。
Preventing Lost Updates
对于写操作引起的冲突,上面只解决了 dirty writes,但两个事务同时写引起的数据丢失还是存在。很多场景下,应用程序采用 read-modify-write 的形式更新数据,会导致前面写的内容被覆盖,比如:
Alice 想给 x 的值增加 50,Bob 想增加 150。那这个过程中,Alice 增加的 50 就被丢掉了。假如这是一个转账的场景,那么这种问题是致命的。另外一个常见场景是,两个人同时编辑一个 wiki 页面,结果后面编辑的人会把前面的人的内容覆盖掉。
对于这个问题,有一些解决方法。
Atomic write operations
数据库提供 原子操作能力,避免需要 read-modify-write 过程。比如:
UPDATE counters SET value = value + 1 WHERE key = 'foo';类似的,MongoDB 和 Redis 也提供了类似能力。但 很多修改并不能很容易用原子操作表达,比如修改一个 wiki 页面。
Explicit locking
显示地对数据上锁,使得即使其他事务想进行读操作,也要等此事务结束。比如 SQL 中的 SELECT ... FOR UPDATE 语句:
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE;
-- Check whether move is valid, then update the position
-- of the piece that was returned by the previous SELECT.
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;但这种方式对应用程序代码要求比较高。需要仔细地考虑哪些操作应该上锁。
Automatically detecting lost updates
使用快照隔离中提出的多版本控制技术,数据库也可以 自动检测 lost updates。事实上 PG 的 repeatable read 会自动检测 lost update,并在这种情况出现时,将会引起问题的事务 abort,使得应用程序可以重新开始 read-modify-write 过程。但 InnoDB 不做这种检测。
Compare-and-set
Compare-and-set 是一种技巧,用来保证修改某一数据时,它的值仍与之前读取出来的一致。比如为了防止两个人同时修改同个 wiki 页面:
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content';Hibernate 提供的锁机制中的 乐观锁(optimistic lock)即基于这种机制。
Conflict resolution and replication
上面提到的锁和 compare-and-set 技术适用于单节点的数据系统,即数据库始终有一份最新的数据。
但分布式的数据系统,可能某一时间点有多份不一样的数据写入了不同结点。常见的处理是允许这种写入,然后再通过应用层去想办法解决或者合并这些多版本的数据(需要深入了解)。
原子操作适用于多节点数据系统。
Write Skew and Phantoms
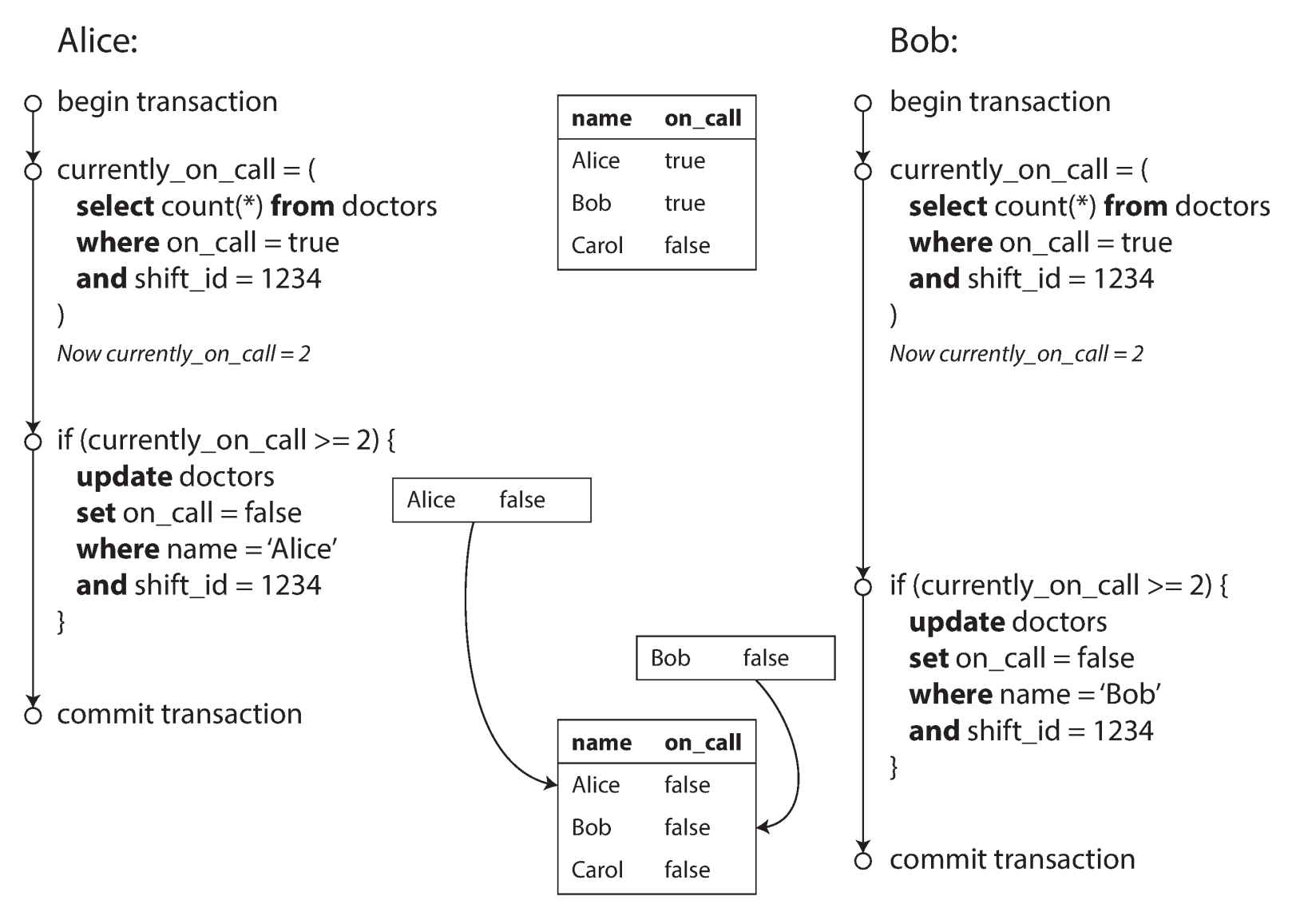
上面是一个 写偏(write skew)的例子。Alice 和 Bob 是医院的医生,原先他们都会在某次轮班(swift_id = 1234)中出勤。医院的规定(暗示一个约束)是,轮班医生可以请假,但轮班至少要有一名医生。但碰巧 Alice 和 Bob 同时申请了请假,而系统在处理请假时判断到该次轮班有两名医生值班,因此均给两位的请假放行,导致该次轮班没有医生出勤(违反了约束)。
总结下写偏的 特点:
- 它的过程不同于 dirty writes 或 lost update,并没有对同一个数据做修改
- 但它可以理解为一种 泛化的 lost update。它是两个事务同时读取一批带有约束条件的数据(值班医生大于 2),但分别修改其中某些数据(分别改各自状态为不出勤),导致约束被违反(violate)的过程。
不太可行的解决方式:
- 之前提到的原子操作(atomic single-object operations)并不适用
- 数据库系统提供的自动检测 lost update 也无法覆盖这种情况
- 数据库提供的约束(constraint)往往只涉及单个对象的(唯一性约束、外键约束等)。多对象的约束可能需要 trigger 或者 materialized view 来实现,但不是广泛被支持
可行的解决方式:
- 隔离级别使用可串行化约束(true serializable isolation)
- 如果无法使用可串行化约束,则使用显式锁是比较好的做法:
BEGIN TRANSACTION; SELECT * FROM doctors WHERE on_call = true AND shift_id = 1234 FOR UPDATE; UPDATE doctors SET on_call = false WHERE name = 'Alice' AND shift_id = 1234; COMMIT;SELECT ... FOR UPDATE会锁住相应的行,使其无法被修改。
像这个订会议室的场景,如果没有可串行化约束,需要应用程序做特别的考虑:
BEGIN TRANSACTION;
-- Check for any existing bookings that overlap with the period of noon-1pm
SELECT COUNT(*) FROM bookings
WHERE room_id = 123 AND
end_time > '2015-01-01 12:00' AND start_time < '2015-01-01 13:00';
-- If the previous query returned zero:
INSERT INTO bookings
(room_id, start_time, end_time, user_id)
VALUES (123, '2015-01-01 12:00', '2015-01-01 13:00', 666);
COMMIT;两个事务同时运行时,可能造成两个人同时订了这个会议室。
这种情况被总结为 幻读(phantom read),即开始的查询会被后续的写操作(INSERT, UPDATE 或 DELETE)影响到,导致一致性没有得到保证。
对于上述订会议室的例子,无法使用锁来做并发控制。但有一种技术思路,实体化冲突(materializing conflicts)可以部分解决这个问题。做法是专门建一个表,里面存放每个会议室每个时间段的纪录,比如每 15 分钟建一行。当有人需要订这个会议室时,把它要订的时间段,在这个表中使用 SELECT FOR UPDATE 锁定起来,这样其他人就无法同时锁定这批时间。这种做法可以解决问题,但是相对复杂,而且不美观,因为需要应用程序去关心这套并发控制。合理的方式还是使用可串行化隔离级别。
Serializability
可串行化隔离(serializable isolation)是最强的隔离级别。它实现的效果是:即使有多个数据库事务并发执行,对于数据库使用者来说,它们也像是串行一个个执行的。
但由于性能问题,但它并不会在所有场景被使用。有三种主流的实现方式:
- 按照字面含义,实际地串行执行事务
- 二阶段锁(two-phase locking, 2PL)
- 乐观的并发控制技术,比如可串行快照隔离(serializable snapshot isolation)
Actual Serial Execution
单线程 地执行事务可以实现可串行化隔离。
但从 70 年代人们开发数据库以来,一直追求通过提升并发来提升性能,因此这种单线程模式并不被考虑。直到 2007 年左右,人们才觉得这个想法是可行的:
- 内存成本降低,使得整个数据集放进内存成为可能。在内存中,事务执行的速度可以远远快过磁盘载体
- 对于 OLTP 而言,事务是比较短的
- 单线程的实现有时候比支持并发的实现性能更好,因为它避免了在并发过程加锁的消耗;但它只能利用单个 CPU
在早期的关系型数据库设计中,设计者想让整个处理过程能封装在一个事务中,例如用户在订机票时,将查询余票、锁定位置、付款等封装到一个过程中。但当数据库不支持并发时,由于用户操作需要时间,意味着第一个用户在订机票时,它的事务一直存在,导致第二个用户无法做任何操作。这是不可接受的。因此设计者发明了 存储过程,它类似于 SQL 语句组成的函数,意图使用一种类似编程语言的方式,将一系列的查询、修改统一放在数据库中执行:
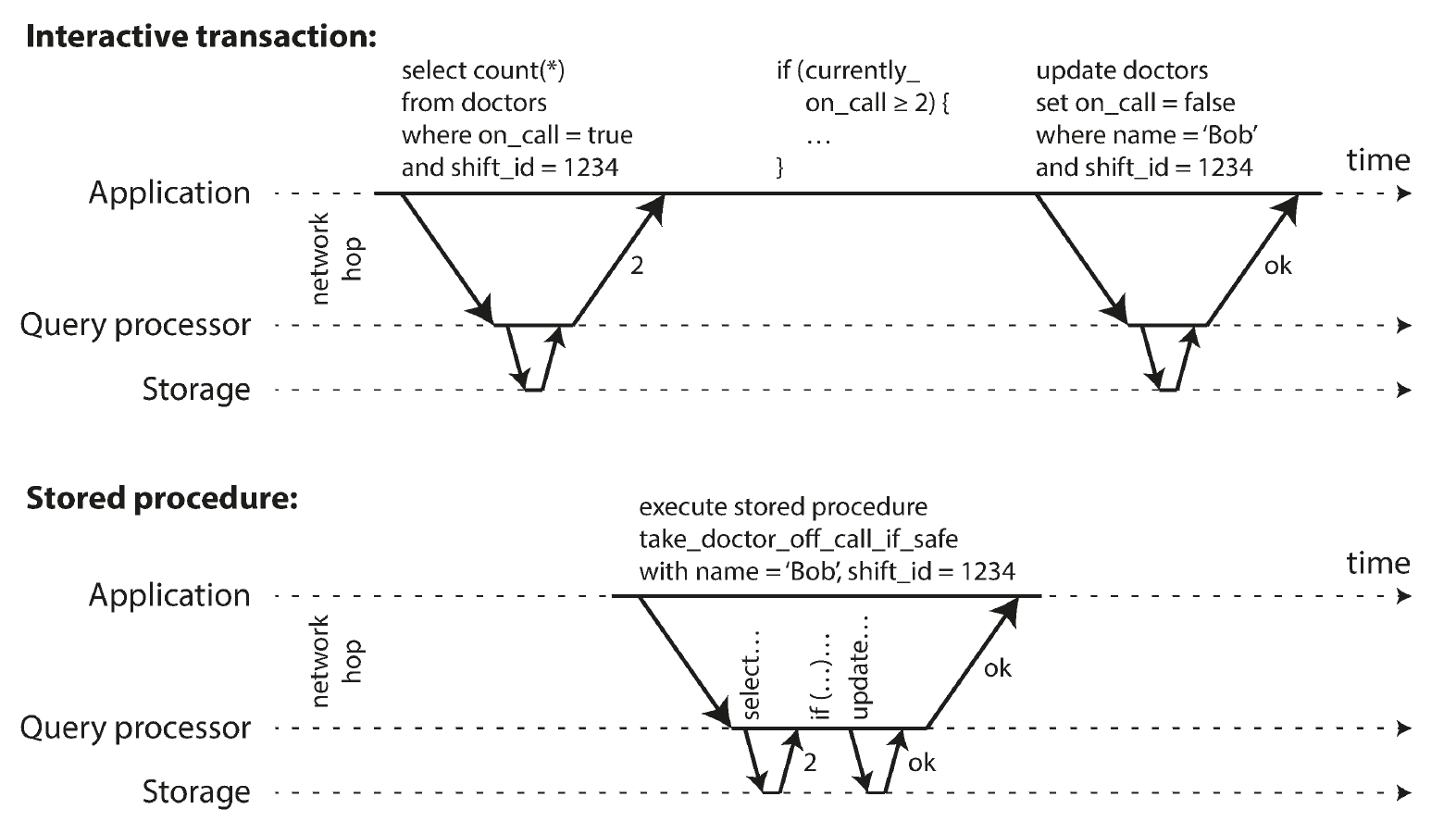
但这种方式没有流行起来,因为:
- 每个数据库系统都有自己一套语言用来描述存储过程,没有统一的规范。而且这些语言的设计过时、丑陋,也缺乏编程库支持
- 存储过程的代码难以调试,需要额外的部署和维护,也对 CVS 不友好
- 写得差的存储过程可能会耗费数据库机器相当多的 CPU 和内存。如果这些逻辑挪到应用程序的机器上实现,即使占用了大量资源,影响面也比前者小
但现代的内存式数据库克服了这些问题。它们抛弃了前辈们发明的语言,而转向更通用的编程语言,比如 VoltDB 用 Java 或 Groovy,Redis 用 Lua。
如果想使内存数据库能利用多核 CPU 提供效率,可以将数据 分区,仅不同的 CPU 可同时处理不同分区的数据。一旦事务需要处理的数据仅在一个分区,它的处理性能会提高很多。如果跨分区,则会有协作带来的性能损耗。VoltDB 是一个例子。
Two-Phase Locking (2PL)
二阶段锁的重点在于,写是独占的。它的规则是:
- 如果事务 A 读了一个 object,
- 事务 B 想读,是可以的
- 事务 B 想写,则要等 A 结束事务
- 如果事务 A 写了一个 object,
- 事务 B 想写或者读,都需要等 A 结束事务
因此 2PL 即会阻塞写,也会阻塞读。
实现上,一般使用两种模式的锁,分别是共享锁(shared mode)和独占锁(exclusive mode)。规则是:
- 如果一个事务想读一个对象,它需要给对象上共享锁。多个事务可以同时给对象加共享锁;但一旦对象被加上独占锁,则其他事务无法加共享锁,需要等待
- 如果一个事务想写一个对象,需要上独占锁;而当一个对象被加上独占锁后,其他事务无法给它加独占锁
- 当一个事务给对象加上锁之后,这些锁直到事务结束才会被释放。这也是 二阶段 的含义所在:第一阶段为事务执行中,加锁;第二阶段为事务结束,释放锁
但这种方式会出现 死锁。数据库可以自动检测死锁,一旦出现就随机中断其中某些事务,使应用程序再去重试。
性能上,一方面 2PL 的性能要比弱隔离差,毕竟有加锁的损耗。但更大的问题是 减少了并发,因为:
- 一旦出现竞争状态或死锁,有一些事务则必须等待或者重试
- 当事务长时间运行时,或者有事务对大量对象加锁时,整个并发会严重下降
但上面的加锁机制解决不了之前描述的会议室预定问题。这种情况下需要 predicate lock。predicate lock 的核心在于,它针对查询条件来加锁,而不是针对读到的 / 要写的对象来加锁。比如:
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00';这种情况下会针对 WHERE 中的条件来加共享锁。之后如果有其他事务修改某一对象时,数据库会检查该对象的 新值和旧值,是否在被事务运行中的事务的 predicate lock 锁定了;如果是,则无法进行加锁。
但这种实现带来了 性能问题。如果数据库中有非常多事务正在运行,去检查每一个 predicate lock 的性能消耗很大。一个折衷的方案是,使用 index-range lock。Index-range lock 的理念是,WHERE 查询语句中的字段往往是有建索引的,比如上面的 room_id。那么数据库可以在索引上加锁,比如认定 room_id = 123 时有锁;虽然这个判定范围更大,不够精确,但是逻辑上是 OK 的。如果其他事务要修改数据时,通过数据查找到相应的索引,即可以比较高性能地判定能否修改
。
Serializable Snapshot Isolation (SSI)
Serializable snapshot isolation (SSI) 是一种比较新的算法。PG 9.1 开始使用 SSI。
2PL 是一种 悲观的并发控制(pessimistic concurrency control)机制:如果事情有可能出错(有锁),那就等到情况变得安全(锁被释放)再继续。
SSI 是一种 乐观(optimistic)的并发控制:即使危险状况出现也让事务继续,期望最终是正常的。它在最终事务提交时 判断隔离有没有被违反,如果有,中断事务并需要应用程序重试。它的缺点是:如果大量事务都读写同一个 object,那么会有大量事务被中断,而后的重试会消耗性能。但反之也是它的优点:大多数情况下同个 object 并不会被大量读写,因此 它会比 2PL 性能更好;而且它的实现是在 snapshot isolation 之上加上检测算法,因此 并不阻塞读的过程。
SSI 可以使用类似 index-range lock 的技术实现。数据库纪录下有查询的 index-range 及修改的数据,然后做判断:

即使修改的数据命中了其他事务之前查询的内容,有些数据库(如 PG)依然能判定这个修改会不会造成影响。如果不造成影响,那么不需要中断事务和回滚。
根据 事务隔离 的维基条目,总结下事务隔离的各级别行为:
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| 未提交读 | 可能发生 | 可能发生 | 可能发生 |
| 提交读 | 不会发生 | 可能发生 | 可能发生 |
| 可重复读 | 不会发生 | 不会发生 | 可能发生 |
| 可串行化 | 不会发生 | 不会发生 | 不会发生 |