%22%20d%3D%22M425.8%2C392.9c-41.5-7.2-83.5-6.3-117.2%2C4.1l-50.5%2C25.5v-4.9h-6.9V416h-5.6%0A%09c-44.7-26.9-97.8-34.7-159.5-23.1v-28.7c0-29.4%2C23.8-53.2%2C53.2-53.2H222c14.2%2C0%2C26.3%2C8.8%2C31.2%2C21.2h6.9v13.3%0A%09c6.8-24.6%2C29.3-42.6%2C56.1-42.6h0c8.9%2C0%2C16.1-7.2%2C16.1-16.1V158.3c0-29.9%2C24.3-54.2%2C54.2-54.2h39.2V346L425.8%2C392.9z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M482.7%2C178.8H378.1c-4.4%2C0-8%2C3.6-8%2C8s3.6%2C8%2C8%2C8h39.6v188.6c-58.5-9.2-110-1-153.6%2C24.6V138.1%0A%09c42.5-27.9%2C94.1-37.1%2C153.6-27.2v45.9c0%2C4.4%2C3.6%2C8%2C8%2C8c0.8%2C0%2C1.6-0.1%2C2.3-0.3c0.7%2C0.2%2C1.5%2C0.3%2C2.3%2C0.3h43c4.4%2C0%2C8-3.6%2C8-8%0A%09s-3.6-8-8-8H469v-14.2c0-4.4-3.6-8-8-8s-8%2C3.6-8%2C8v14.2h-19.2v-44.6c0-3.9-2.7-7.2-6.5-7.9c-66.2-12.4-123.8-2.9-171.3%2C28.1%0A%09c-47.5-31-105.1-40.5-171.3-28.1c-3.8%2C0.7-6.5%2C4-6.5%2C7.9v22.4H50.3c-4.4%2C0-8%2C3.6-8%2C8v287.8c0%2C4.4%2C3.6%2C8%2C8%2C8h203.6%0A%09c0.6%2C0.1%2C1.2%2C0.2%2C1.7%2C0.2c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.6%2C0%2C1.2-0.1%2C1.7-0.2H461c4.4%2C0%2C8-3.6%2C8-8V194.8h13.8%0A%09c4.4%2C0%2C8-3.6%2C8-8S487.2%2C178.8%2C482.7%2C178.8z%20M58.3%2C142.5H78V366c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8V110.9c59.5-9.8%2C111.1-0.7%2C153.6%2C27.2V408%0A%09c-45.9-26.9-100.7-34.7-163.1-23c-4.3%2C0.8-7.2%2C5-6.4%2C9.3c0.8%2C4.3%2C5%2C7.2%2C9.3%2C6.4c52.1-9.8%2C98.4-5.2%2C137.9%2C13.6H58.3V142.5z%0A%09%20M453%2C414.4H286.4c39.5-18.8%2C85.8-23.4%2C137.9-13.6c2.3%2C0.4%2C4.8-0.2%2C6.6-1.7c1.8-1.5%2C2.9-3.8%2C2.9-6.2V194.8H453V414.4z%22%3E%3C%2Fpath%3E%0A%3Cpath%20fill%3D%22%23FCCF31%22%20class%3D%22primary-color%22%20d%3D%22M80.7%2C19.7L19.8%2C80.7V19.7H80.7z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M483.7%2C50.2c0%2C4.4-3.6%2C8-8%2C8h-15.8V74c0%2C4.4-3.6%2C8-8%2C8s-8-3.6-8-8V58.2h-15.8c-4.4%2C0-8-3.6-8-8s3.6-8%2C8-8h15.8V26.4%0A%09c0-4.4%2C3.6-8%2C8-8s8%2C3.6%2C8%2C8v15.8h15.8C480.1%2C42.2%2C483.7%2C45.8%2C483.7%2C50.2z%20M30.6%2C462.1c-5.9%2C0-10.8%2C4.8-10.8%2C10.8s4.8%2C10.8%2C10.8%2C10.8%0A%09s10.8-4.8%2C10.8-10.8S36.5%2C462.1%2C30.6%2C462.1z%20M228.4%2C26.7C213.9%2C26.7%2C202%2C38.5%2C202%2C53c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8%0A%09c0-5.7%2C4.7-10.4%2C10.4-10.4s10.4%2C4.7%2C10.4%2C10.4c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8C254.8%2C38.5%2C243%2C26.7%2C228.4%2C26.7z%22%3E%3C%2Fpath%3E%0A%3C%2Fsvg%3E) Designing Data-intensive Applications
Designing Data-intensive Applications介绍 reliability, scalability, 和 maintainability 的含义,以及实现它们的手段。
这里将最常见的数据处理需求列出来了:
A data-intensive application is typically built from standard building blocks that provide commonly needed functionality. For example, many applications need to:
- Store data so that they, or another application, can find it again later (databases)
- Remember the result of an expensive operation, to speed up reads (caches)
- Allow users to search data by keyword or filter it in various ways (search indexes)
- Send a message to another process, to be handled asynchronously (stream processing)
- Periodically crunch a large amount of accumulated data (batch processing)
不同的数据系统(主要指软件层面,如 MySQL、ElasticSearch 等)会有自己的特性,来满足上述一些场景的需求。
Thinking About Data Systems
背景:
Data system 分类的 边界模糊:
- Redis 即可以做 cache,也有人使用它做消息队列
- Apache Kafka 即是消息队列,也提供了类似数据库的持久化
一个工具往往不能满足全部业务需求,比如下面是一个可能的业务架构图:
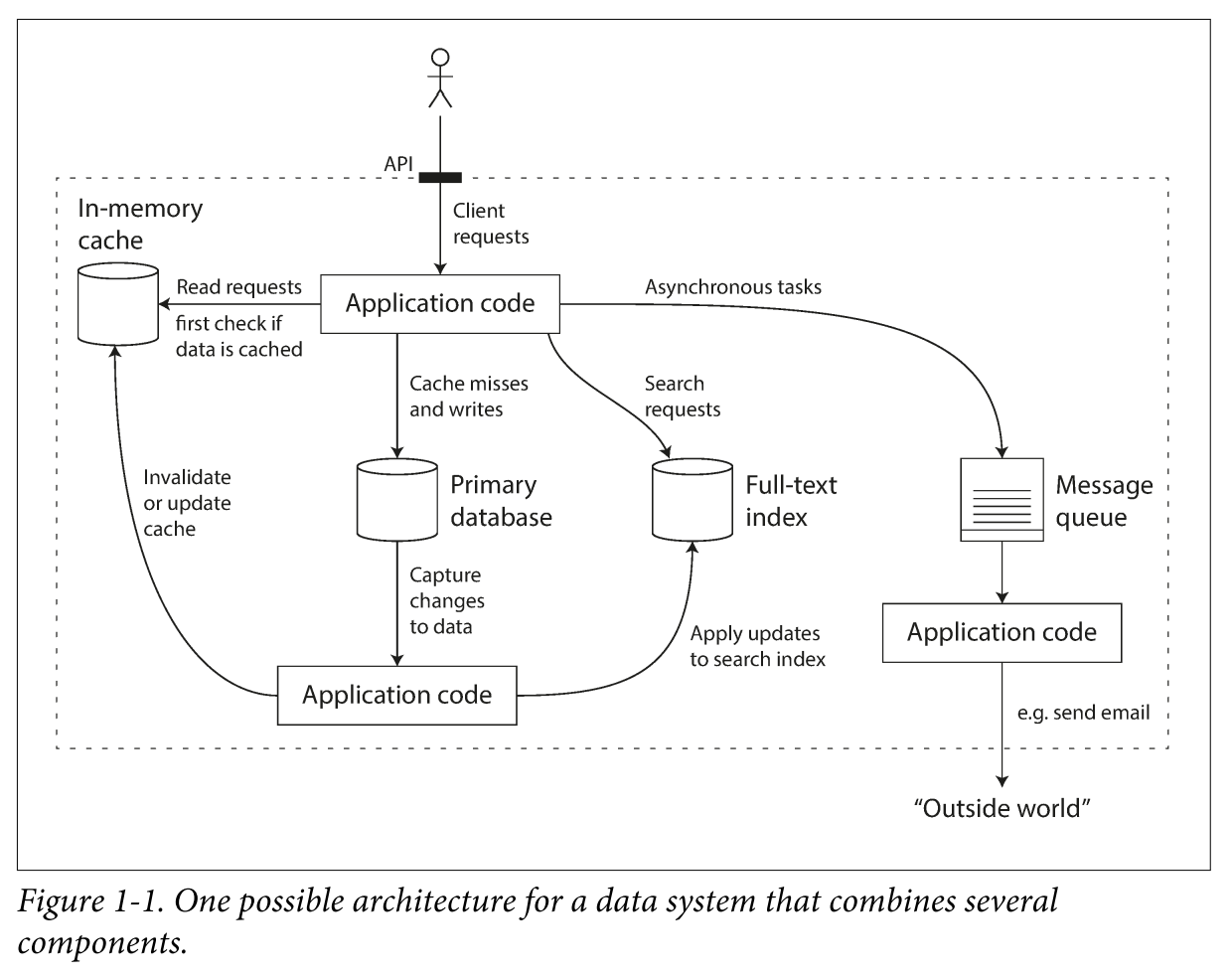
这个系统是由一些通用组件构建出来的特殊系统,需要考虑:
- 如何保证缓存数据的一致性?
- 如何保证出错时数据保持正确和完整?
- 当部分组件不工作、系统降级时,如何仍然保持系统整体性能?
- 负载增加时如何扩容?
- 服务提供的 API 应该是怎样的?
问题:
如何判断使用怎样的系统?各个系统在设计上有什么共通点?
解答:
不同系统间一般有 3 个共同要考虑的点:
- 可靠性(Reliability):即使出现异常情况,软件也能正常运行
- 可伸缩性(Scalability):可以应对负载的增加
- 可维护性(Maintainability):系统可以容易地进行变更来使其顺利运行,比如可以容易地打补丁、发布修复 bug 后的应用等
这一章下面的内容在阐述这几点具体的含义。
Reliability
定义:
「可靠性」,
- 简单地说:continuing to work correctly, even when things go wrong.
- 复杂地说:
- The application performs the function that the user expected.
- It can tolerate the user making mistakes or using the software in unexpected ways.
- Its performance is good enough for the required use case, under the expected load and data volume.
- The system prevents any unauthorized access and abuse.
错误相关的概念:
- Faults: things go wrong
- Cope with (certain kinds of) faults: fault-tolerant or resilient.
Faults v.s. failure:
- Faults 一般指单个组件的功能没有满足要求
- Failure 一般是系统整体出现错误,无法满足要求。如果没有做好错误处理,fault 可能会演变为 failure
Netflix Chaos Monkey: 有意地破坏系统中一些组件,产生 fault,以演习和测试整个系统的可靠性。
并不是全部 fault 都是可以被 tolerant 的,比如有安全漏洞导致数据库信息被黑客盗取。
下面描述各种不同类型的 fault。
Hardware Faults
现状:
硬件错误是非常常见的:机房断电、运维插错电缆造成网络配置错误、内存或者硬盘坏掉。一个硬盘平均 10-50 年会挂掉,如果像数据中心那样多的硬盘,几乎每天都会有硬盘挂掉。
解决方法:
Add redundancy(增加冗余):硬盘上 Raid,机房多路供电,上 UPS。
但是……
并不是任何一种应用都需要强调单机的可用性。比如一个互联网应用的逻辑层 server,往往会有数十台甚至上千台机器,依赖于前端的负载均衡和高可用机制,一台机器挂掉了也有其他机器继续服务,影响并不大。比较依赖于单机可用性的,可能是一些关键的数据库服务等。
Software Error
关联性:
硬件错误往往不是相关联的,比如一台机器硬盘挂了,并不代表其他机器也会同时挂掉。但是软件错误往往是「系统性的」,比如 Linux Kernel 的一个 bug 可能会影响非常多的服务;一个服务可能返回了错误的信息给到上游,导致上游也出现异常。
潜伏性:
软件中的 bug 经常在于代码对它的运行环境有一些预设的认识。一般情况下环境的情况符合这个认识,但是一旦不符合了,bug 就会引起错误。
解决办法:
编程时多思考;详尽的测试;进程隔离;出错时 crash 并重启;监控及分析线上系统等。
Human Errors
现状:
人不可靠。事实上互联网中的服务不可用,绝大多数是来自运维操作或者配置出问题。硬件故障引起的问题只占很小一部分。
解决办法:
- 设计一个不容易犯错的系统。比如 API、管理界面上,把容易出错的部分抽象或者屏蔽掉,只留下容易理解的、好用的接口供用户操作。
- 提供机制,使用户即使犯了错也不会引起问题。比如提供沙箱环境,让开发可以拿线上数据做分析,但是又不会影响到用户环境
- 做仔细的测试,覆盖系统的各个层级;做自动化测试
- 提供快速恢复的机制;比如发布配置或者发布程序的平台,提供快速回滚的机制
- 建立详细且清晰的监控机制,使得出错时能快速定位问题
- 通过管理和培训的手段来减少误操作的发生
How Important Is Reliability?
通常都非常非常重要。如果是做原型,可以为了开发速度适当牺牲可靠性。
Scalability
指如何去应对负载(load)增加。
Describing Load
<<.s "问题:"" >>
如果无法清晰描述 负载(load),那么也无法知道什么是负载增加,以及如何应对。
解决过程中引入的概念:
负载,一般拆分成多个 负载因素(load parameters)来描述,根据你的系统架构而有无不同,比如:
- requests per second to a web server
- the ratio of reads to writes in a database
- the number of simultaneously active users in a chat room
- the hit rate on a cache
Twitter 例子:
Twitter 的场景是读多(300k rps)写少(4.6k rps)。一般有两种方案:
- 发推时写帐号自身的存储,读 timeline 时从关注的全部帐号中拉取帖子并进行合并和排序
- 发推时写帐号自身的存储,同时更新到关注者的缓存中;这样读 timeline 时不用去拉关注的帐号的内容进行合并
在读多写少的场景下,第二种方案的性能事实上比第一种好。但是 Twitter 有个特点时,部分名人有些非常多的关注量(上百万甚至千万),用第二种时会导致名人发帖时要写入的数据非常多,无法及时送达到全部关注者。最终 Twitter 结合了这两种方案来解决这个问题。
在这个场景中,Twitter 的 关键负载因素,是用户的粉丝数分布(以及他们发推的频率)。你的系统根据自身的特点,也可能有它独特的负载因素。
Describing Performance
从实际问题出发……
- 如果把一个负载因素增加(比如请求量增长一倍),保持系统资源不变(如 CPU、带宽、机器数等),你的系统的性能会受到怎样的影响?
- 接上,如果你希望系统性能不变,需要增加多少资源?
应该如何描述性能?
不同类型的系统,用来描述性能的指标不一样。比如 Hadoop 类批处理系统(batch processing system),一般以 吞吐量(throughput,即单位时间内处理的纪录数)来衡量。线上系统则一般以 响应时间(response time)来衡量。
不同请求的响应时间各不一样。一般观察响应时间的 分布情况 来做判断:
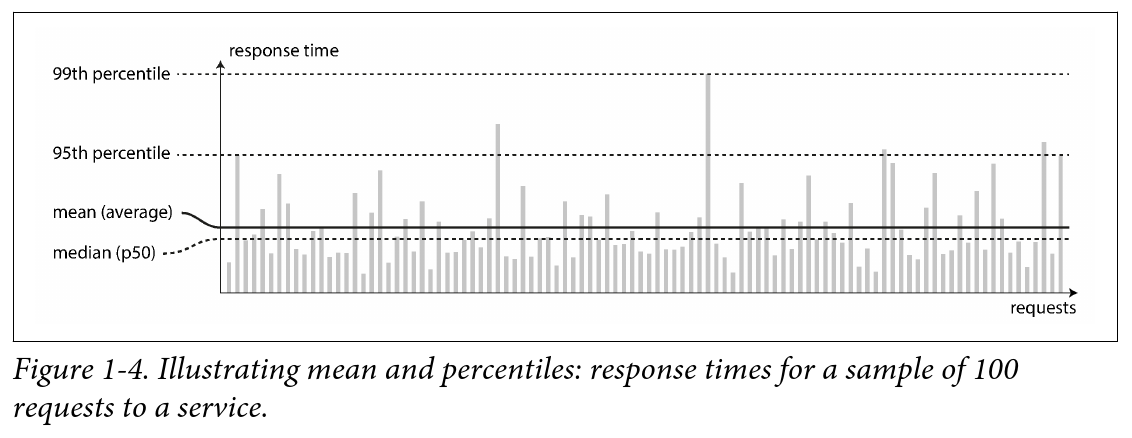
一般来说各请求的处理时间都应该是一致的,但是一些因素会引起的额外的延时,导致各请求响应时间不一致。比如进程切换、TCP 丢包重传、GC 引起进程中断等等。
从分布情况中,一般考虑这些点:
- 使用 percentiles 来衡量大部分请求的时延情况,比如 p95(即最快的 95% 的请求落在什么范围内),以及 p99、p999 等;这个方法能得出绝大部分用户的情况
- 不考虑 使用平均数(mean / average),因为对于延时变化很大的场景,它并不能体现什么
有时候 p999 会显著大于 p95。High percentiles of response time,被称为 tail latencies。有些场景需要着重考虑 tail latency。比如亚马逊中,处理得最慢的请求往往是下单量很大的客户,他们的数据多导致了处理过慢。到了 p9999 时,优化最慢的请求往往已经变得性价比不高,因此对于 tail latency 的处理应该有合理的评估。
非核心内容
service level objectives (SLOs) 和 service level agreements (SLAs),往往是以 percentiles 的形式描述的。比如 p50 的响应时间是 200ms,p99 的响应时间在 1s 内。服务的当机时间少于 0.1% 等等。
Head-of-line blocking(队头阻塞),是指后台程序在按顺序处理请求时,有部分请求执行时间过长,导致其后的请求在队列中等待了太长时间,从而引起整个系统性能降低的问题。
如果场景是用户需要发多个并行请求(比如动态加载内容的网页),并在全部请求都返回后才能处理(例如渲染出整个网页),那么最慢的请求会最终影响性能。这叫 tail latency amplification,放大了 tail latency 带来的影响。
- Note
- Latency(延时)与 response time 并不一样。Response time 是指客户端观察到的延时,包含了网络传输、请求在队列中等待被处理的时间等。Latency 则仅包含请求被程序实际执行的时间。
Approaches for Coping with Load
应对负载增加的方法
常见的两种说法:
- Scaling up: 换更好的硬件,让单台机器更强(Stack Overflow 在很长一段时间是 这样做 的)
- Scaling out: 堆更多的机器,是现在互联网服务常见的模式
有些系统是弹性的(elastic),可以根据负载变化自动扩缩机器。缺点是系统变复杂、可能应对不了一些异常的流量增长等。
无状态服务容易做 scaling out。有状态服务难。以前的惯常做法是,对数据库使用 scaling up 模式。但是未来 分布式数据库应该是标配。
Scaling Architecture 的考虑点
没有一个适配任何场景的 scaling architecture。考虑点有:数据存储的大小,读写数据的量,数据的复杂度,响应时间要求等等。比如一个 100,000 RPS,每次请求处理 1kB 数据的系统,与每分钟 3 次请求,每次处理 2GB 数据的系统,他们处理的数据量是一样的,但是架构完全不一样。
非核心内容
对于创业团队,如果想法未被市场验证,应该优先开发速度而不是架构设计。因为设计出来的 scaling architecture 可能跟后面业务的模式不匹配,导致无用功。
Maintainability
可维护性中的「维护」,包含了修复 bug、维护系统正常运转、增加新功能等等。考虑 Operability、Simplicity 及 Evolvability。
Operability: Making Life Easy for Operations
主要讲运维应该做什么事情来维护系统顺利运转。如监控、问题定位、打安全补丁、容量预估、运维工具开发、文档维护等等。
Simplicity: Managing Complexity
复杂的软件系统出 bug 机率高、维护成本高。
复杂的功能可以通过 抽象,使得软件实现上简单直观。
Evolvability: Making Change Easy
应对需求变化、外界环境变化、商业模式变化等等情况,你的系统需要是可随时进化的。这往往构建在 simplicity 的基础上。但是作者说这个很重要,要单独列出来。