%22%20d%3D%22M425.8%2C392.9c-41.5-7.2-83.5-6.3-117.2%2C4.1l-50.5%2C25.5v-4.9h-6.9V416h-5.6%0A%09c-44.7-26.9-97.8-34.7-159.5-23.1v-28.7c0-29.4%2C23.8-53.2%2C53.2-53.2H222c14.2%2C0%2C26.3%2C8.8%2C31.2%2C21.2h6.9v13.3%0A%09c6.8-24.6%2C29.3-42.6%2C56.1-42.6h0c8.9%2C0%2C16.1-7.2%2C16.1-16.1V158.3c0-29.9%2C24.3-54.2%2C54.2-54.2h39.2V346L425.8%2C392.9z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M482.7%2C178.8H378.1c-4.4%2C0-8%2C3.6-8%2C8s3.6%2C8%2C8%2C8h39.6v188.6c-58.5-9.2-110-1-153.6%2C24.6V138.1%0A%09c42.5-27.9%2C94.1-37.1%2C153.6-27.2v45.9c0%2C4.4%2C3.6%2C8%2C8%2C8c0.8%2C0%2C1.6-0.1%2C2.3-0.3c0.7%2C0.2%2C1.5%2C0.3%2C2.3%2C0.3h43c4.4%2C0%2C8-3.6%2C8-8%0A%09s-3.6-8-8-8H469v-14.2c0-4.4-3.6-8-8-8s-8%2C3.6-8%2C8v14.2h-19.2v-44.6c0-3.9-2.7-7.2-6.5-7.9c-66.2-12.4-123.8-2.9-171.3%2C28.1%0A%09c-47.5-31-105.1-40.5-171.3-28.1c-3.8%2C0.7-6.5%2C4-6.5%2C7.9v22.4H50.3c-4.4%2C0-8%2C3.6-8%2C8v287.8c0%2C4.4%2C3.6%2C8%2C8%2C8h203.6%0A%09c0.6%2C0.1%2C1.2%2C0.2%2C1.7%2C0.2c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.6%2C0%2C1.2-0.1%2C1.7-0.2H461c4.4%2C0%2C8-3.6%2C8-8V194.8h13.8%0A%09c4.4%2C0%2C8-3.6%2C8-8S487.2%2C178.8%2C482.7%2C178.8z%20M58.3%2C142.5H78V366c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8V110.9c59.5-9.8%2C111.1-0.7%2C153.6%2C27.2V408%0A%09c-45.9-26.9-100.7-34.7-163.1-23c-4.3%2C0.8-7.2%2C5-6.4%2C9.3c0.8%2C4.3%2C5%2C7.2%2C9.3%2C6.4c52.1-9.8%2C98.4-5.2%2C137.9%2C13.6H58.3V142.5z%0A%09%20M453%2C414.4H286.4c39.5-18.8%2C85.8-23.4%2C137.9-13.6c2.3%2C0.4%2C4.8-0.2%2C6.6-1.7c1.8-1.5%2C2.9-3.8%2C2.9-6.2V194.8H453V414.4z%22%3E%3C%2Fpath%3E%0A%3Cpath%20fill%3D%22%23FCCF31%22%20class%3D%22primary-color%22%20d%3D%22M80.7%2C19.7L19.8%2C80.7V19.7H80.7z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M483.7%2C50.2c0%2C4.4-3.6%2C8-8%2C8h-15.8V74c0%2C4.4-3.6%2C8-8%2C8s-8-3.6-8-8V58.2h-15.8c-4.4%2C0-8-3.6-8-8s3.6-8%2C8-8h15.8V26.4%0A%09c0-4.4%2C3.6-8%2C8-8s8%2C3.6%2C8%2C8v15.8h15.8C480.1%2C42.2%2C483.7%2C45.8%2C483.7%2C50.2z%20M30.6%2C462.1c-5.9%2C0-10.8%2C4.8-10.8%2C10.8s4.8%2C10.8%2C10.8%2C10.8%0A%09s10.8-4.8%2C10.8-10.8S36.5%2C462.1%2C30.6%2C462.1z%20M228.4%2C26.7C213.9%2C26.7%2C202%2C38.5%2C202%2C53c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8%0A%09c0-5.7%2C4.7-10.4%2C10.4-10.4s10.4%2C4.7%2C10.4%2C10.4c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8C254.8%2C38.5%2C243%2C26.7%2C228.4%2C26.7z%22%3E%3C%2Fpath%3E%0A%3C%2Fsvg%3E) Designing Data-intensive Applications
Designing Data-intensive Applications数据模型经常是一层叠一层的:
- 应用开发者一般会将现实世界的内容抽象成数据结构并提供 API 操作它们。这些数据结构一般是不通用的,仅适用于你的应用程序
- 为了存储或者展示这些数据,你经常需要使用 JSON / XML 文档,或者关系型数据库中的表等等
- 你所使用的数据库软件,会决定这些数据(比如关系型数据库中的表)在内存、磁盘或者网络上是怎样表现的,并且决定这些数据可以怎样被查询、修改等
- 在更底层,硬件工程师决定了各个字节怎样用电流、脉冲、磁场等形式来表示
Data models 有很多种,各自适合一些不同的场景。按你的应用的特性,选择好相应的 data models 是非常重要的事情。
Relational Model Versus Document Model
Relational model 一开始被使用于事务处理(银行交易、航班预订等)和批处理上。后来变得通用化。同期的其他模型,如 network model 和 hierarchical model 都发展不起来。
The Birth of NoSQL
NoSQL 在 2010s 开始流行开来。NoSQL 表示 Not Only SQL,目标是为了避免或者解决 relational model 中的一些问题:
- 提高扩展性(scalability),特别是在大的数据集(dataset)和非常高的写入量时
- 优先使用开源软件而不是商业软件
- 支持一些 relational model 中无法比较好支持的查询方式
- 支持比 relational schema 更灵活、有表达力的数据模型
The Object-Relational Mismatch
普遍存在对 SQL 数据模型的一个批判是,它引入了 impedance mismatch,即在业务代码和数据库数据间需要一层转换(比如把一行数据转为一个类实例)。比如下面 Bill Gates 的简历中,涉及一对多的部分(Experience, Education, Contact Info),需要用额外的表来存储:
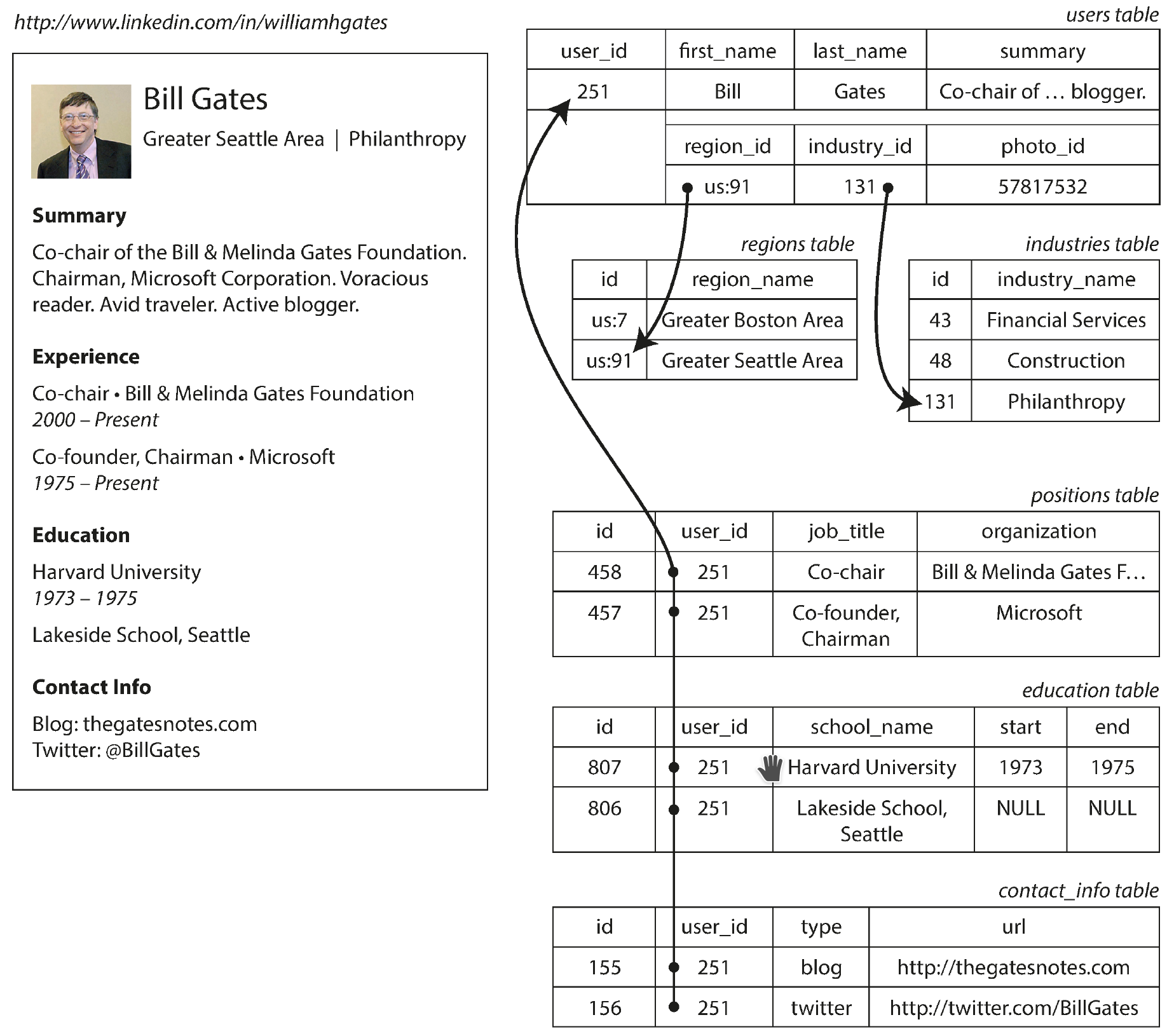
当然新的 SQL 标准也加入了一些对结构化数据的支持,比如可以定义一个列为 JSON 数据,并对里面的 key 做索引等。不过这些能力并没有被广泛应用。
像简历这种 self-contained document,用 JSON 来表达是比较合适的。面向文档的数据库,如 MongoDB,RethinkDB 等支持这种数据模型:
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation"},
{"job_title": "Co-founder, Chairman", "organization": "Microsoft"}
],
"education": [
{"school_name": "Harvard University", "start": 1973, "end": 1975},
{"school_name": "Lakeside School, Seattle", "start": null, "end": null}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}JSON model:
- 减少了 impedance mismatch,业务代码和数据模型结合更紧密
- 增进了 locality,查同样的内容,RDBMS 需要多次查询或者联表查询,document-oriented database 只需要一次
- Lack of schema:这个特性存在争论,有优点也有缺点,后面会有
Many-to-One and Many-to-Many Relationships
问题:
上面的例子中,为什么表示区域和行业时,要选择 ID(region_id, industry_id)而不是直接用字符串(如 "Greater Seatlle Area" 和 "Philanthropy")来表示?
原因:
用 ID 可以实现:
- 一致的样式和拼写
- 避免含糊不清(比如多个城市带有同个名字)
- 容易更新,比如城市名发生变化后
- 容易实现本地化,以别的语言展示
- 更好进行搜索,比如后台如果纪录了西雅图是华盛顿中的一个城市,那么搜「华盛顿里的慈善家」也可以搜索出 Bill Gates
用 ID 的好处是,它本质上对于人类来说没有含义,所以即使它背后的数据发生了变化,ID 本身也不用变。用 ID 也可以避免用具体文本带来的需要批量更新问题。去除数据库中的重复数据,这个过程称之为 normalization。
Many-to-one Relationships and Many-to-many Relationships:
多对一关系(many-to-one relationships),比如「很多人居住在某个城市」(一般人只会居住在一个城市)。多对多关系(many-to-many relationships),比如「人们任职过某家公司」,一个人可能任职过多家公司,多家公司也可能有过不同的人任职。
对于这两种关系,一般适合在 RDBMS 中 normalize(因为有 join),但是在 document database 中则难以做到,它们的 join 能力一般会差一点。对于这种情况,你可能需要在应用代码中去做 join 的工作,比如发起多个数据库查询请求。
另外,即使 document database 适用于一开始的数据模型,但是随着业务发展,数据往往会倾向于互相有联系。
Are Document Databases Repeating History?
并没有。60s-70s 讨论过的 network model 和 hierachy model 对应用代码来说,使用的负担很重。
Relational Versus Document Databases Today
这一章主要从 data model 层面来做对比。
Which data model leads to simpler application code?
视你的业务形态而定。如果业务逻辑中有很多 many-to-one / many-to-many relationships,那么 RDBMS 合适。如果是 one-to-many 居多,或者有 collection 中的元素类型不定,可以考虑 document-based。
Schema flexibility in the document model
schema-on-read v.s. schema-on-write:
Document database 经常被称作 schemaless,但是这是不准确的。实现上数据的结构、类型是隐式的,仅在数据被读取时才被解释出来,因此称之为 schema-on-read 更合适。而 RDBMS 也可以被称作 schema-on-write,即数据库会保证写入的数据符合 schema 的定义。
类比:
- Document databases, schema-on-read, 类似动态语言的运行时类型检查
- RDBMS, schema-on-write, 类似静态语言的编译期类型检查
Data Migration:
Data Migration 涉及的数据变化的种类,见 Data Migration。
RDBMS 利用 “statically typed” database schema 的特性,可以在 DB 层面提供支持:
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQLDocument database 则没有 DB 层面的 migration 功能,一般有这么几种做法:
- 单独写脚本去负责数据的迁移和回滚
- 数据在业务代码中被读取时才更新。这会带来额外的代码复杂度。
Data locality for queries
对于读取:
- 如果读的数据,对于 relational model 来说需要多次联表,对于 document model 则不需要查多次,因此后者的数据本地性(data locality)强,即可以消耗更少的时间、I/O 查询出结果
- 如果 document 比较大,但是每次只需要读取其中一小块数据,那么 RDBMS 可能性能更佳
对于写入:
- 如果 document 比较大,但是写入时仅需要更新其中部分字段,那么:
- 如果写后 document 的体积没有显著变大,那么一般 document database 可以做到 in-place update,对性能影响小(参考 MongoDB 文章,关键字 "in-place update)
- 如果写后 document 的体积显著变大,则难以做到 in-place update,需要整个 document 重写进数据库,对性能影响大
- RDBMS 一般比较少存在这种问题
将关联的数据放在一起以增加本地性,必不仅是 document database 的做法。Google Spanner Database, Oracle, HBase 等均有类似的功能。
Convergence of document and relational databases
document database 和 relational database 都在互相采纳对方优秀的点:
- 一些 RDBMS(如 MySQL,Postgres)支持将 XML / JSON 数据作为一列并将里面数据进行索引
- 一些 document database 支持 join,如 RethinkDB
- 一些 MongoDB driver 会在 client 通过多次查询模拟 join
Query Languages for Data
Imperative v.s. declarative
- SQL: a declarative query language
- IMS and CODASYL queried the database using imperative code
Declarative (声明式):
SELECT * FROM animals WHERE family = 'Sharks';Imperative (指令式):
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}声明式描述想要的最终结果。指令式描述处理的过程。声明式在数据库领域取得了胜利,它的好处有:
- 对于使用者友好,更简单明了,使用者无需知道数据库底层工作原理
- 相对声明式,对数据库软件来说更容易优化,比如数据库可以在不影响上层用户使用的情况下,对引擎进行优化,利用多核 CPU 等特性
Declarative Queries on the Web
Declarative query 不仅局限于数据库。网页上也有类似的例子。考虑下面的 HTML 结构:
<ul>
<li class="selected">
<p>Sharks</p>
<ul>
<li>Great White Shark</li>
<li>Tiger Shark</li>
<li>Hammerhead Shark</li>
</ul>
</li>
<li>
<p>Whales</p>
<ul>
<li>Blue Whale</li>
<li>Humpback Whale</li>
<li>Fin Whale</li>
</ul>
</li>
</ul>如果你想将被选中的元素(class="seleted")的标题(<p>)的背景色置为蓝色,你可以用 CCS 表达,它是声明式的:
li.selected > p {
background-color: blue;
}如果不用声明式而用指令式,那么你可以用 JavaScript 这样写:
var liElements = document.getElementsByTagName("li");
for (var i = 0; i < liElements.length; i++) {
if (liElements[i].className === "selected") {
var children = liElements[i].childNodes;
for (var j = 0; j < children.length; j++) {
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
child.setAttribute("style", "background-color: blue");
}
}
}
}这里的 JS 对应上面 CSS 的方法,有一些明显缺陷:
- JS 更长更难读懂
- 如果
selectedclass 被动态移除(比如用户点击了别的<li>),JS 的方案并不会自动去掉蓝色背景;但是 CSS 的方案中,浏览器会自动检测到变化并去掉蓝色背景 - 如果 DOM 出了新的性能更好的 API,JS 需要被重写才能得到优化。但是如果是 CSS,优化可以被浏览器自己实现,不需要使用者关心
MapReduce Querying
MapReduce 是一个被用来在多台机器同时处理大量数据的 编程模型。它的实现介于 declarative 和 imperative 之间:处理数据的逻辑是用代码表达的,同时这些代码被框架所重复执行。
例子:
你是个海洋生物学家,你想统计每个月观察到的鲨鱼数量。
纯命令式:
你可以在 PostgreSQL 数据库里面这样写:
SELECT date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;Using MongoDB’s MapReduce Feature:
db.observations.mapReduce(
function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
function reduce(key, values) {
return Array.sum(values);
},
{
query: { family: "Sharks" },
out: "monthlySharkReport"
}
);比如像这样的 observations:
[{
observationTimestamp: Date.parse("Mon, 25 Dec 1995 12:34:56 GMT"),
family: "Sharks",
species: "Carcharodon carcharias",
numAnimals: 3
},
{
observationTimestamp: Date.parse("Tue, 12 Dec 1995 16:17:18 GMT"),
family: "Sharks",
species: "Carcharias taurus",
numAnimals: 4
}]会先经过 map 处理,emit 出两个 k-v 对,("1995-12", 3), ("1995-12", 4)。这两个 k-v 对在 reduce 时被聚合,reduce("1995-12", [3, 4]),结果返回 7。
总结:
对于 MapReduce 模型而言,map 和 reduce 函数是指令式的,你可以在里面实现简单的处理逻辑。整个框架是指令式的,一般框架都会将数据切分成多块到多台机器并行 map,最终再 reduce 回来。
一般 map 及 reduce 函数的实现,都必须是纯函数,即无副作用的。比如他们不能查询数据库,或者对外部数据有修改,而仅仅应该接受输入参数的数据并做处理。这使得框架可以以任意顺序运行函数,或者失败时进行重试。
MapReduce 模型并 不是 分布式数据处理的必须。很多数据库也实现了分布式处理,但是不用 Map-Reduce。SQL 的语法并不关心底层是 Map-Reduce 还是其他实现。
扩展:
MapReduce 的编写难度相对高,而且 DB 引擎难对其进行优化。因此 MongoDB 也提供了一种声明式查询语言 aggregation pipeline:
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{
$group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
}
}
]);这可能是 JSON 形式的 SQL reinvent。
Graph-Like Data Models
- Note
- 这种数据模型在应用上不广泛,在比较少的领域,如数据分析、知识图谱、SEO 优化等场景被使用到。
这类模型适用于关系非常复杂的场景:
- 社交网络图,人是点(vertices),关系是线(edges)
- 网页图,页面是点,页面上的超链接是线
- 铁路图等
这类模型中的典型问题之一,计算两地的最短距离。
点(vertex)所表示的数据,不一定需要是相同类型的(homogeneous)。比如 Facebook 中,点即可以代表一个人,也可以代表打卡过的地方、评论和事件等等。
下面是一个图所结构化的示例:

Property Graphs
Property graph model:
- 每个点由这些信息组成:
- 唯一 ID
- 一组以此点为起点的边
- 一组以此点为终点的边
- 一组 k-v 对,用来表示属性
- 每个边由这些信息组成:
- 唯一 ID
- 边的起点(the tail vertex)
- 边的终点(the head vertex)
- 一个标签(label),用来表示两个点间的关系
- 一组 k-v 对,用来表示属性
如果用关系型数据库的表来表达:
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
properties json
);
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFERENCES vertices (vertex_id),
label text,
properties json
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);这种模型灵活性很高。你可以表示不同颗粒度的信息,比如 Lucy 的当前居住地为具体某一城市,但是它的出生地可以只标记在州这一级别。扩展性也很高。你可以往图中不停加入新数据,比如将 Lucy 的过敏源纪录进来,并纪录各过敏源所对应的食物,这样就可以判断出 Lucy 不能吃哪些食物。
The Cypher Query Language
Cypher 是 property graph 模型的一个声明式的查询语言。上面的例子用 Cypher 出来是这样的:
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state'}),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)有了数据后,我们就可以用 Cypher 查询出想的数据,例如查询出生在欧洲,但是居住在美国的人群:
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name上面的例子表示要找到任何满足下面条件的人:
- 它有一个 outgoing 的
BORN_IN边,边的终点通过WITHIN链([:WITHIN*0..])最终指向name为United States的点 - 它有一个 outgoing 的
LIVES_IN边,边的终点通过WITHIN链([:WITHIN*0..])最终指向name为Europe的点
- Note
- 如果有
person的数据是直接BORN_INUnited States 而不是下面的具体地区,这条查询也是能查到数据的。因为-[:WITHIN*0..]->表示要匹配的点可以没有 outgoing 的WITHINlabel。
使用指令式时,数据库引擎可以自动选择最高效的方式来执行查询,
- 它即可以从
Person数据开始,找到最终的Location数据; - 也可以从
Location数据开始筛选,最终反向找到需要的Person
Graph Queries in SQL
SQL 也可以表达上面的查询,但是会复杂很多。需要使用 recursive common table expressions。这里不详细描述。
Triple-Stores and SPARQL
Triple-Stores 的基本原理是,将数据表达为 (subject, predicate, object) 组成的三元对,比如 (Jim, likes, bananas)。其中:
subject,对应 property graph 中的 vertexobject,- 可以是原子类型(如字符串或者数字),对应 property graph 中 vertex 的 properties
- 也可以是图表中的另外一个 vertex,此时三元对对应 property graph 中的边
predicate则类似于 property graph 中的边的 label
例如:
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location.
_:usa :name "United States".
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location.
_:namerica :name "North America".
_:namerica :type "continent".Triple-Stores 在设计之初并没有准备作为 semantic web 的实现手段,但是在 2000s 开始讨论并流行的 semantic web 风潮借鉴了它。The semantic web 认为网页已经是 human-readable 的了,那么为何不更进一步将其中的数据,变成 machine-readable 呢?期望最终达成 a kind of internet-wide “database of everything”。但是一直没有好的实现出现,同时标准屡次修改,后来并没有被推广开。
在此过程中产生了 Resource Description Framework (RDF)。RDF 虽然也是 triple-store 的理念,但是使用 XML。同时产生了 SPARQL (SPARQL Protocol and RDF Query Language),它是一门设计得不错的查询语言,后来前文提到的 Cypher 借鉴了它:
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}The Foundation: Datalog
Datalog 这门查询语言比 SPARQL 及 Cypher 更老,在 80 年代被广泛用于教学上。它的一个实现,Cascalog,被使用在 Hadoop 的数据处理和查询功能中。
Datalog 的数据模型与 triple-store 类似,但它使用的是更泛化的 predicate(subject, object),如:
name(namerica, 'North America').
type(namerica, continent).
name(usa, 'United States').
type(usa, country).
within(usa, namerica).
name(idaho, 'Idaho').
type(idaho, state).
within(idaho, usa).
name(lucy, 'Lucy').
born_in(lucy, idaho).对于之前用其他模型实现过的,查询生于欧洲但是现居住于美国的人,可以这样实现:
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */
within_recursive(Location, Name) :- within(Location, Via), /* Rule 2 */
within_recursive(Via, Name).
migrated(Name, BornIn, LivingIn) :- name(Person, Name), /* Rule 3 */
born_in(Person, BornLoc),
within_recursive(BornLoc, BornIn),
lives_in(Person, LivingLoc),
within_recursive(LivingLoc, LivingIn).
?- migrated(Who, 'United States', 'Europe').
/* Who = 'Lucy'. */对比于 Cypher 和 SPARQL 使用一条 SELECT 语句查出结果,Datalog 采用了更渐进式的方式来做。上面定义了三条规则,用来告诉数据库如何生成新的 predicate,比如 within_recursive 及 migrated。然后用这些新的 predicate 进行查询。
理解这几条规则的要点在于:
- 大写字母开头的表示变量,如 Location, Name, Via 等
- 每提供一条规则给到数据库,数据库会按此规则扫描现有的 predicate 并生成新的 predicate
- 生成新的 predicate 的前提是,
:-操作符中定义的条件需要全部满足
例如:
// Existed predicate applied with rule 1, new predicate generated:
+ name(namerica, 'North America')
=> within_recursive(namerica, 'North America')
// Existed predicate, cooperate with predicated generated in previous rule, applied with rule 2:
+ within(usa, namerica)
+ within_recursive(namerica, 'North America')
=> within_recursive(usa, 'North America')下面的图描述了这一过程:
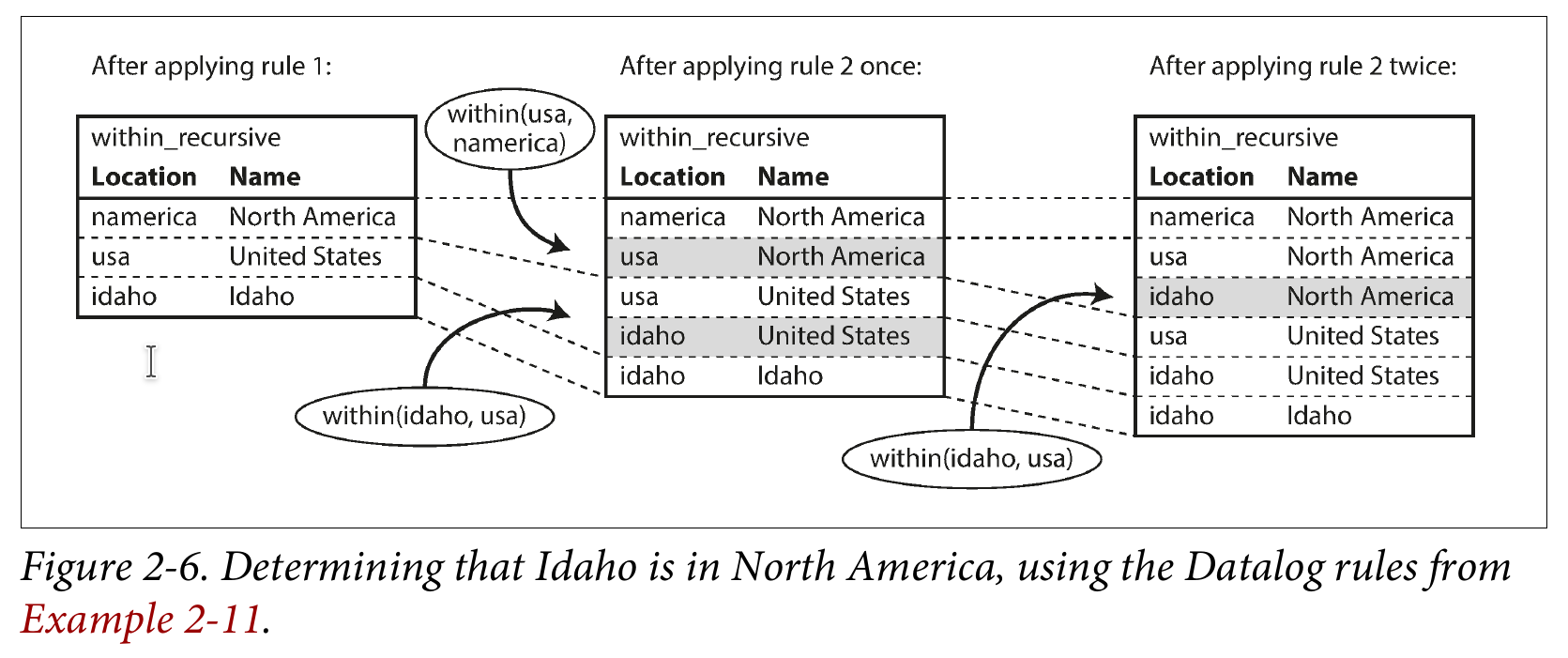
Datalog 的查询方式,在写一次性查询时会略显啰嗦,但是在处理复杂数据时会更强大更易理解。