%22%20d%3D%22M425.8%2C392.9c-41.5-7.2-83.5-6.3-117.2%2C4.1l-50.5%2C25.5v-4.9h-6.9V416h-5.6%0A%09c-44.7-26.9-97.8-34.7-159.5-23.1v-28.7c0-29.4%2C23.8-53.2%2C53.2-53.2H222c14.2%2C0%2C26.3%2C8.8%2C31.2%2C21.2h6.9v13.3%0A%09c6.8-24.6%2C29.3-42.6%2C56.1-42.6h0c8.9%2C0%2C16.1-7.2%2C16.1-16.1V158.3c0-29.9%2C24.3-54.2%2C54.2-54.2h39.2V346L425.8%2C392.9z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M482.7%2C178.8H378.1c-4.4%2C0-8%2C3.6-8%2C8s3.6%2C8%2C8%2C8h39.6v188.6c-58.5-9.2-110-1-153.6%2C24.6V138.1%0A%09c42.5-27.9%2C94.1-37.1%2C153.6-27.2v45.9c0%2C4.4%2C3.6%2C8%2C8%2C8c0.8%2C0%2C1.6-0.1%2C2.3-0.3c0.7%2C0.2%2C1.5%2C0.3%2C2.3%2C0.3h43c4.4%2C0%2C8-3.6%2C8-8%0A%09s-3.6-8-8-8H469v-14.2c0-4.4-3.6-8-8-8s-8%2C3.6-8%2C8v14.2h-19.2v-44.6c0-3.9-2.7-7.2-6.5-7.9c-66.2-12.4-123.8-2.9-171.3%2C28.1%0A%09c-47.5-31-105.1-40.5-171.3-28.1c-3.8%2C0.7-6.5%2C4-6.5%2C7.9v22.4H50.3c-4.4%2C0-8%2C3.6-8%2C8v287.8c0%2C4.4%2C3.6%2C8%2C8%2C8h203.6%0A%09c0.6%2C0.1%2C1.2%2C0.2%2C1.7%2C0.2c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.6%2C0%2C1.2-0.1%2C1.7-0.2H461c4.4%2C0%2C8-3.6%2C8-8V194.8h13.8%0A%09c4.4%2C0%2C8-3.6%2C8-8S487.2%2C178.8%2C482.7%2C178.8z%20M58.3%2C142.5H78V366c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8V110.9c59.5-9.8%2C111.1-0.7%2C153.6%2C27.2V408%0A%09c-45.9-26.9-100.7-34.7-163.1-23c-4.3%2C0.8-7.2%2C5-6.4%2C9.3c0.8%2C4.3%2C5%2C7.2%2C9.3%2C6.4c52.1-9.8%2C98.4-5.2%2C137.9%2C13.6H58.3V142.5z%0A%09%20M453%2C414.4H286.4c39.5-18.8%2C85.8-23.4%2C137.9-13.6c2.3%2C0.4%2C4.8-0.2%2C6.6-1.7c1.8-1.5%2C2.9-3.8%2C2.9-6.2V194.8H453V414.4z%22%3E%3C%2Fpath%3E%0A%3Cpath%20fill%3D%22%23FCCF31%22%20class%3D%22primary-color%22%20d%3D%22M80.7%2C19.7L19.8%2C80.7V19.7H80.7z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M483.7%2C50.2c0%2C4.4-3.6%2C8-8%2C8h-15.8V74c0%2C4.4-3.6%2C8-8%2C8s-8-3.6-8-8V58.2h-15.8c-4.4%2C0-8-3.6-8-8s3.6-8%2C8-8h15.8V26.4%0A%09c0-4.4%2C3.6-8%2C8-8s8%2C3.6%2C8%2C8v15.8h15.8C480.1%2C42.2%2C483.7%2C45.8%2C483.7%2C50.2z%20M30.6%2C462.1c-5.9%2C0-10.8%2C4.8-10.8%2C10.8s4.8%2C10.8%2C10.8%2C10.8%0A%09s10.8-4.8%2C10.8-10.8S36.5%2C462.1%2C30.6%2C462.1z%20M228.4%2C26.7C213.9%2C26.7%2C202%2C38.5%2C202%2C53c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8%0A%09c0-5.7%2C4.7-10.4%2C10.4-10.4s10.4%2C4.7%2C10.4%2C10.4c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8C254.8%2C38.5%2C243%2C26.7%2C228.4%2C26.7z%22%3E%3C%2Fpath%3E%0A%3C%2Fsvg%3E) Designing Data-intensive Applications
Designing Data-intensive Applications这一章讨论了 数据库系统如何高效地存储、读取数据。
根据用途不同,存储引擎的设计也不同:
- 针对事务性的(transactional)场景,一般有两类存储引擎,分别是 log-structured 和 page-oriented
- 针对分析(analytics)数据的场景,还有 column-oriented
下面会分别针对这几种存储引擎进行分析。
Data Structures That Power Your Database
这一节构建了一个简单的基于纪录(log-structured)的数据库,存在一个名为 database 的数据库中,为 key-value 形式,每一行前面的逗号即为 key:
$ cat database
123456,{"name":"London","attractions":["Big Ben","London Eye"]}
42,{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
42,{"name":"San Francisco","attractions":["Exploratorium"]}查找数据时,需要线性遍历文件数据,根据纪录数的变化,查询所需时间也线性变化,时间复杂度为 。写入数据时,只往后追加数据,不修改原有的数据。追加数据是顺序写,I/O 的消耗最少;如果在原地修改原有数据,假如新数据长度大于原数据,会造成后面大量数据需要重写,影响性能。
为了加速查询,引入 索引(index)来辅助记录数据库的元信息。索引会增加写入数据时的消耗(因为需要更新索引),但是会加速查询。
Hash Indexes
前置的总结,log-structured 数据库的要点,涵盖了 Hash Indexes 和 SSTables and LSM-Trees 两节的内容:
最简单的索引是 哈希索引,即纪录每个 key 所对应的纪录在数据库文件中的位置:
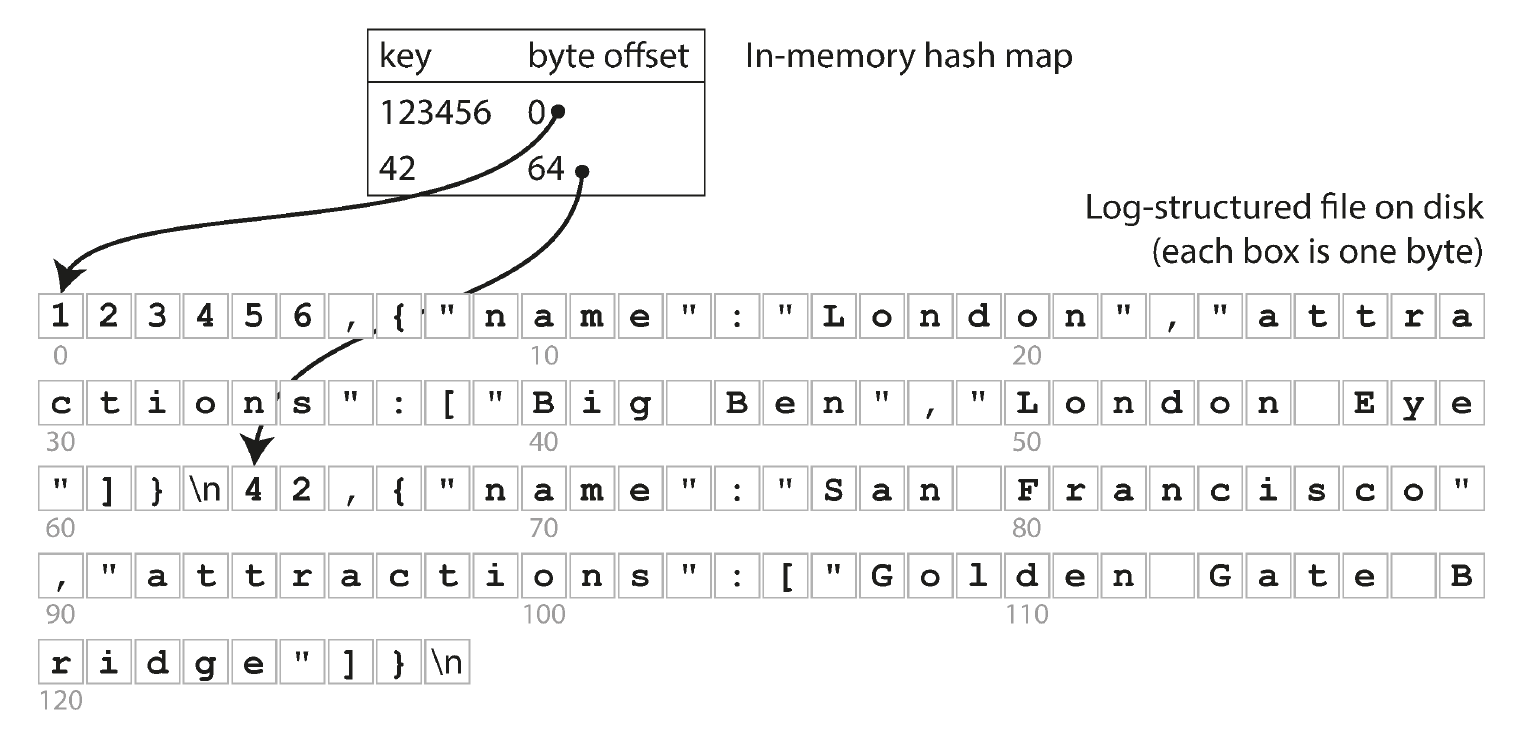
另外,由于写数据时都是 追加写,这会导致
- 数据库文件 无限膨胀,可能超过文件系统能支持的单文件大小
- 一个 key 可能出现多条纪录,但只有最后的纪录是有效的,还可能消耗完所有的磁盘空间
数据库文件分片(data file segment)及数据压缩(compaction)用来解决这个问题。文件分布的意思时,数据库不在集中在一个文件中,而是可以分散在多个文件中。压缩是指把同个 key 的老数据清理掉。一般来说,压缩会在一个单独的背景线程下工作,一旦压缩完成,生成新的 segment 文件和索引后,数据库便可以使用新的索引和数据文件,再把老的索引和文件删除:

上述的模型只考虑了简单的点。其他重要的细节包括:
- 文件格式(file format)
- CSV 作为文本格式在性能上不如二进制格式。应考虑使用二进制格式。
- 删除纪录(deleting records)
- 如果要删除一个 key,应该向数据库写进一条删除纪录。这样数据库在压缩合并分片文件时,可以将这个 key 的纪录全部删除。
- 崩溃恢复(crash recovery)
- 重启时需要扫整个数据库文件以重建索引,比较耗时。一个优化点时,将索引也落盘以省去重建过程。
- 只写了部分数据的纪录(partially written records)
- 数据库可能在写纪录写一半时崩溃。需要加个校验码等机制来确保数据是完整的。如果数据校验时不一致,可以丢弃掉不一致的数据。
- 并发控制(concurrency control)
- 假如有两个请求同时要求写入数据,可能会引起数据库文件混乱。一个解决方法是只提供一个写入线程。
这种模型的 缺点 是:
- 用来作为索引的哈希表需要存在内存中。如果 key 数量太多,内存可能不够用。在磁盘上使用哈希表性能差,经常需要大量随机 I/O 访问,而且也不易实现
- 很难做范围查询。比如查
kitty00000到kitty99999之间的所有数据时,需要遍历整个哈希表
SSTables and LSM-Trees
Sorted string table(SSTables)指文件分片(segment)是排好序的。这种形式的好处是:
- 压缩合并分片文件时性能更高,对内存要求更少
- 不用全部纪录都落索引,可以只落一部分。其他 key 在数据文件中的位置,通过已有的索引进行判断
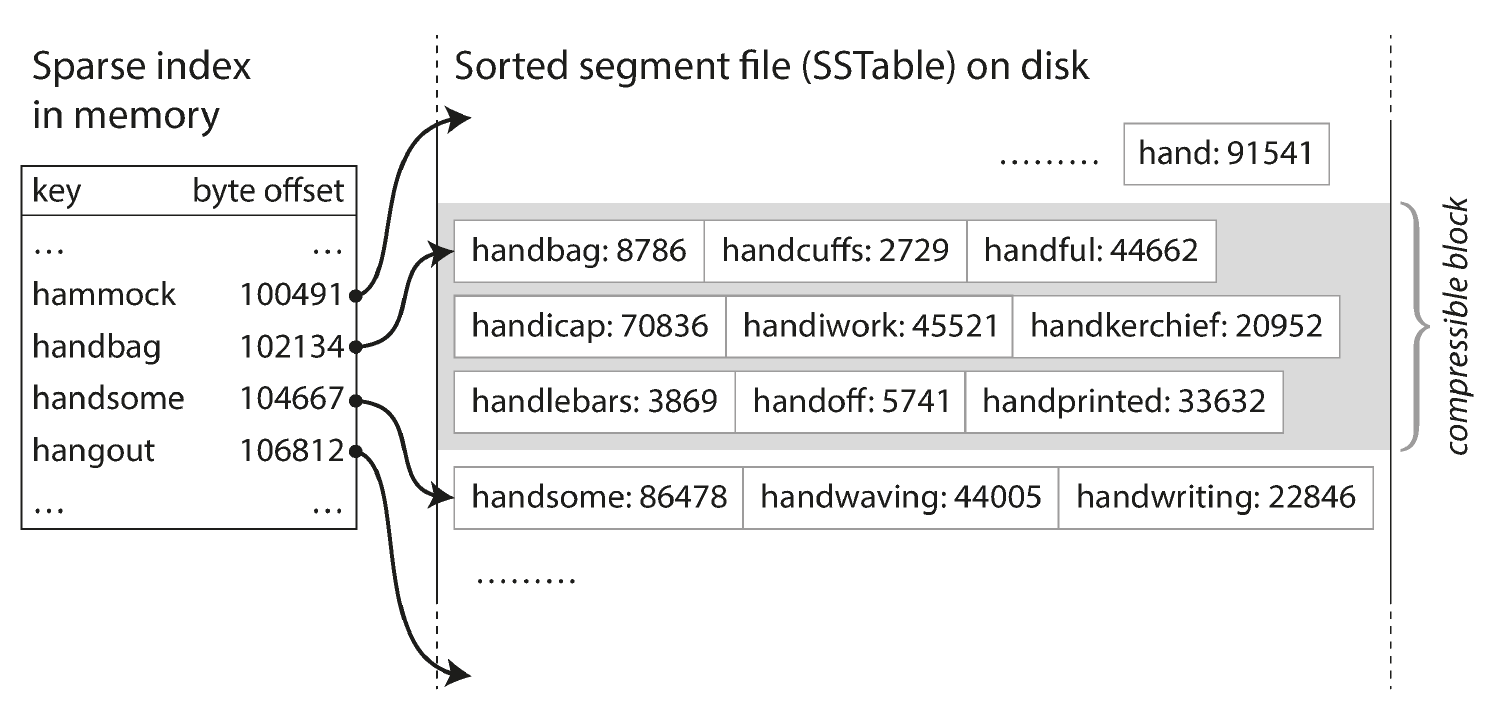
再进一步,由于 hash table 没有排序且存储在磁盘中难高效使用,Log-Structured Merge-Tree(LSM-Tree)是更好的选择。这类树结构可以将 key 排好序,一般用红黑树或者平衡树实现。好处是:
- 写入数据时写进这个树结构中(有时称之为 memtable),不再直接写到数据文件中
- 等树中的新纪录数量达到一定程度时,再结合压缩合并过程,将其落盘
- 写一个单独的 WAL 防 crash
上述的各种方案中,如果 key 不存在,都需要查索引以及查询所有分片文件。可以用 bloom filter 来快速判断一个值在不在数据文件中,避免这部分查询的消耗。
B-Trees
B-tree 是用于索引时最流行的数据结构。笔记纪录在 B-Tree。
Comparing B-Trees and LSM-Trees
| 数据库类型 | B-Tree | LSM-Trees |
|---|---|---|
| 写入的数据量 | 数据至少要写两次,分别是 WAL 以及数据页 修改数据时需要更新整个页带来额外消耗 | 压缩合并过程也大量写入 |
| 写入的吞吐量 | 较低 | 较高,因为写入时是顺序写 |
| 占用磁盘空间 | 大,因为页中会有未使用的空间 | 小,而且由于数据有序,可以压缩 |
| 响应的平滑度 | 优 | 稍差, 在压缩合并过程会有大量 I/O 发生,导致有些请求无法被快速处理 数据量越多,压缩合并时的 I/O 消耗越大 |
| 需要事务的场景 | 优,锁可以直接加在树上 | 差 |
Other Indexing Structures
如果索引中的 key 不唯一(即一个 key 可能有多行),两种方法:
- 每个 key 的值为一个包含多行的列表
- 每个 key 与其下的每个行中的唯一标识(一般是主键)组合成一个复合的 key
Storing values within the index
数据库查询发生时,一般会先在索引中查找 key。而 key 所关联的行(或者 NoSQL 中的 document、图数据库中的 vertex),可以跟索引存在一起,也可以单独存在另外的位置。
这两种情况下的索引,分别称作:
- 聚簇索引(clustered index):数据与索引保存在一起
- 非聚簇索引(nonclustered index):索引只保存到数据的引用
非聚簇索引下,数据 存在另外的位置,这个数据文件被称为 heap file。heap file 特征:
- 使用广泛,可以在多级索引的场景下避免数据重复
- 如果更新数据库纪录时没有修改 key 本身,那只需修改 heap file 而不需要动到索引
- 如果修改后的数据量不超过原有的,可以实现 原地修改(overwritten in place),是比较高效的
索引 key 与其关联的数据存在一起时,这个索引被称为 聚簇索引。InnoDB 的主键即是聚簇索引,其他二级索引会指向主键索引。
这两种方式的折中是,使用 covering index 或称 index with included columns,即保留表的一些常用列到索引中。这样当查询只查到这些列时,索引就能覆盖(cover)到了,不再需要去查 heap file。但这种数据的重复,会带来额外的写消耗,以及需要额外的代码保证一致性。
Multi-column indexes
前文所述的是基于单列的索引。如果有多列一起形成的索引,有几种方法:
- 使用 concatenated index,即把多列的值连起来合成一个值。但查询时要遵循 最左前缀原则(leftmost prefix)(MySQL 文档),不然无法使用索引
- 使用 multi-dimensional indexes。这种方式不再使用 B-tree,而一般使用 R-tree。PostGIS 是一个例子。我没有深究
Full-text search and fuzzy indexes
上述索引进行的是 精确匹配,但在搜索的场景往往需要 模糊匹配。给定一个搜索词,可以搜近义词、修正 typo、忽略语法上的不同变化(比如过去式)等等。ES 中的 Lucene 是一个例子。实现细节文中没有深究。
Keeping everything in memory
内存数据库(in-memory database)是将数据主要放在内存中的数据库。特点:
- 内存访问速度快,但空间小,单位存储成本高
- 内存掉电后丢失数据
- 有些实现,如 Memcache,只作缓存层,因此数据丢失只要再重新缓存
- 有些实现会定期将数据落盘或者通过网络发给备机,数据丢失时重建
- 内存数据库的性能优势,不在于可以从内存(而不是硬盘)读取,因为假如数据不多,基于硬盘的数据库中的数据也经常被 OS 缓存在内存中;而在于 不需要维持一个用于写入硬盘的数据结构,比如 B 树
- 不仅仅是 key-value 型,也 可提供关系模型,还可提供 RDBMS 不容易实现的复杂数据结构,比如优先级队列和集合
- 通过换页,也可支持数据量比内存更大的情况
Transaction Processing or Analytics
Transaction processing 并非指数据库中的、带 ACID 能力的事务功能,而是指通常意义的「一个业务操作」,比如添加一个条目、发送一条消息等等。它通常要求客户端请求的延时低,对比于早期的批处理系统。
Analytics 指数据分析,即通过数据库做统计和分析,比如本月的收益有多少。
对这两者的处理,分别叫做:
- OLTP (online transaction processing)
- OATP (online analytic processing)
对比如下(直接摘抄书中表格):
| Property | Transaction processing systems (OLTP) | Analytic systems (OLAP) |
|---|---|---|
| Main read pattern | Small number of records per query, fetched by key | Aggregate over large number of records |
| Main write pattern | Random-access, low-latency writes from user input | Bulk import (ETL) or event stream |
| Primarily used by | End user/customer, via web application | Internal analyst, for decision support |
| What data represents | Latest state of data (current point in time) | History of events that happened over time |
| Dataset size | Gigabytes to terabytes | Terabytes to petabytes |
早期的大家使用同样的数据库做事务性处理和统计分析。后来随着数据库发展,有 专门的数据库被设计出来处理数据分析。
Data Warehousing
数据仓库中的数据,一般是从线上数据库中通过转存(dump)或者流式更新(continuous stream of updates)复制过来的。在此过程中,会做数据变换、清理成适合分析的形式,再落入数据仓库中。这个过程叫作 Extract-Transform-Load(ETF):
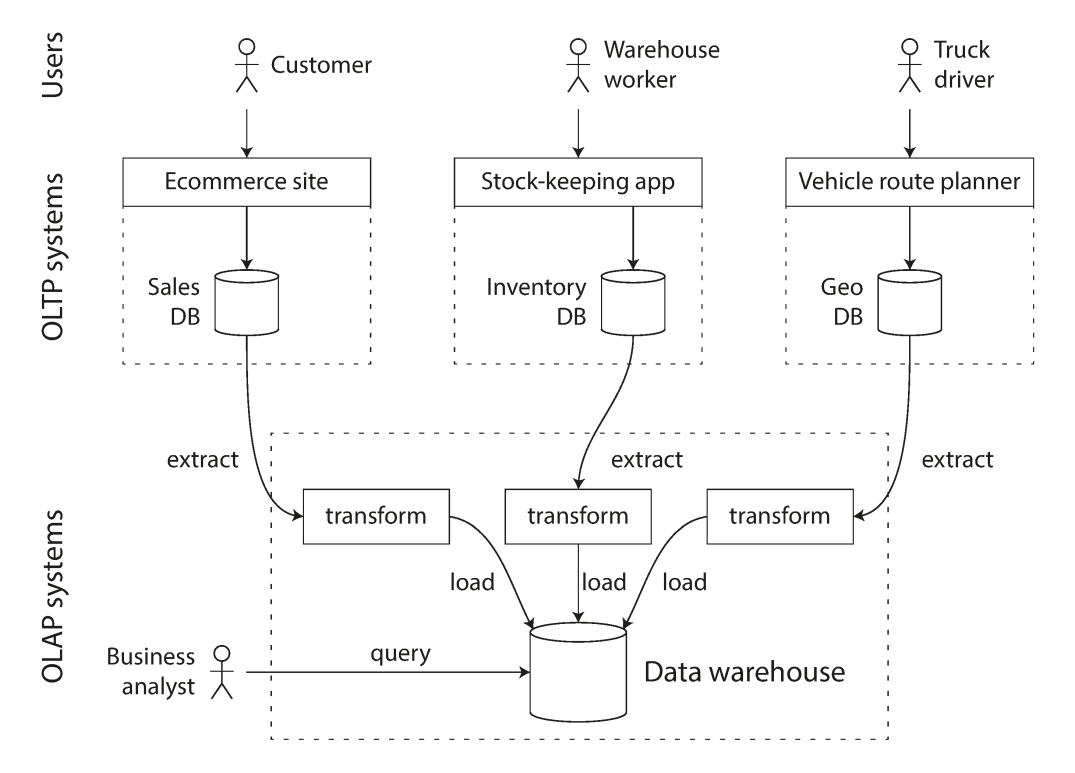
数据仓库为分析的场景做了优化,它的索引结构跟 RDBMS 不太一样。但书中也没有继续深入。
数据仓库大多数也支持 SQL 查询。
Stars and Snowflakes: Schemas for Analytics
在数据仓库中,大多数的数据 schema 是类似这样的星形,由一个中心的 fact 表格引用非常多 dim(维度,dimension)表格:
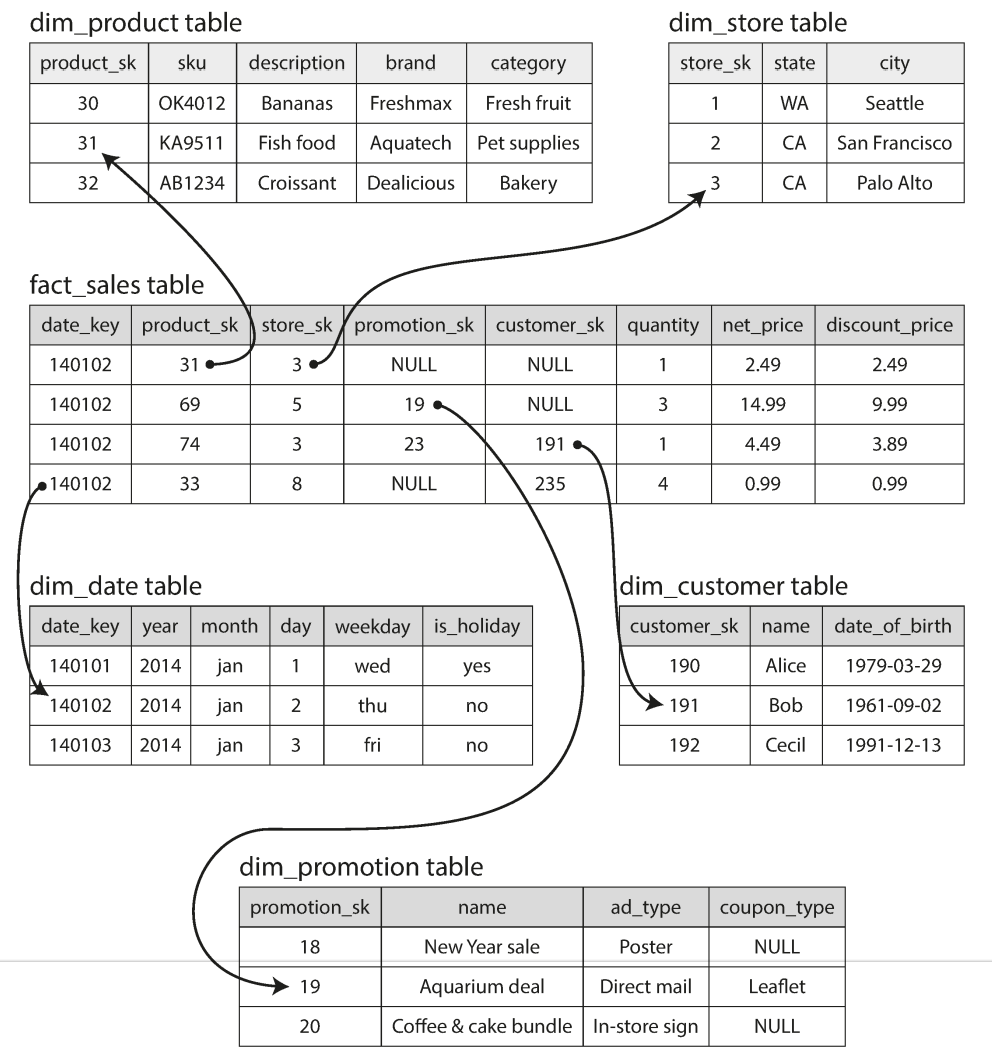
与此类似,还有雪花形的 schema,即是 dim 表也引用其他的 dim 表。
Column-Oriented Storage
大多数的 OLTP 数据库中,数据是以行的形式保存的(row-oriented)。但有一些场景下,一个表的列非常多(100+),而你只需要使用其中的几列。如果在 row-oriented 的数据库中,你需要读完整的一行,而行中的绝大多数数据是你不需要的,非常耗性能。而有些 OLAP 系统实现了 column-oriented,即 数据是按的形式存储,这样只使用其中几行时,效率非常高。
Column Compression
由于同一列中的数据,类型和数据往往相近且取值范围小,因此适合做压缩。比如数据仓库中经常使用的 bitmap encoding 来做压缩:

上面的例子中,product_sk 的取值只有非常少的 6 种,因此适合用 bitmap encoding。当遇到这种查询时:WHERE product_sk IN (30, 68, 69),数据仓库也能高效处理。