%22%20d%3D%22M425.8%2C392.9c-41.5-7.2-83.5-6.3-117.2%2C4.1l-50.5%2C25.5v-4.9h-6.9V416h-5.6%0A%09c-44.7-26.9-97.8-34.7-159.5-23.1v-28.7c0-29.4%2C23.8-53.2%2C53.2-53.2H222c14.2%2C0%2C26.3%2C8.8%2C31.2%2C21.2h6.9v13.3%0A%09c6.8-24.6%2C29.3-42.6%2C56.1-42.6h0c8.9%2C0%2C16.1-7.2%2C16.1-16.1V158.3c0-29.9%2C24.3-54.2%2C54.2-54.2h39.2V346L425.8%2C392.9z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M482.7%2C178.8H378.1c-4.4%2C0-8%2C3.6-8%2C8s3.6%2C8%2C8%2C8h39.6v188.6c-58.5-9.2-110-1-153.6%2C24.6V138.1%0A%09c42.5-27.9%2C94.1-37.1%2C153.6-27.2v45.9c0%2C4.4%2C3.6%2C8%2C8%2C8c0.8%2C0%2C1.6-0.1%2C2.3-0.3c0.7%2C0.2%2C1.5%2C0.3%2C2.3%2C0.3h43c4.4%2C0%2C8-3.6%2C8-8%0A%09s-3.6-8-8-8H469v-14.2c0-4.4-3.6-8-8-8s-8%2C3.6-8%2C8v14.2h-19.2v-44.6c0-3.9-2.7-7.2-6.5-7.9c-66.2-12.4-123.8-2.9-171.3%2C28.1%0A%09c-47.5-31-105.1-40.5-171.3-28.1c-3.8%2C0.7-6.5%2C4-6.5%2C7.9v22.4H50.3c-4.4%2C0-8%2C3.6-8%2C8v287.8c0%2C4.4%2C3.6%2C8%2C8%2C8h203.6%0A%09c0.6%2C0.1%2C1.2%2C0.2%2C1.7%2C0.2c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.6%2C0%2C1.2-0.1%2C1.7-0.2H461c4.4%2C0%2C8-3.6%2C8-8V194.8h13.8%0A%09c4.4%2C0%2C8-3.6%2C8-8S487.2%2C178.8%2C482.7%2C178.8z%20M58.3%2C142.5H78V366c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8V110.9c59.5-9.8%2C111.1-0.7%2C153.6%2C27.2V408%0A%09c-45.9-26.9-100.7-34.7-163.1-23c-4.3%2C0.8-7.2%2C5-6.4%2C9.3c0.8%2C4.3%2C5%2C7.2%2C9.3%2C6.4c52.1-9.8%2C98.4-5.2%2C137.9%2C13.6H58.3V142.5z%0A%09%20M453%2C414.4H286.4c39.5-18.8%2C85.8-23.4%2C137.9-13.6c2.3%2C0.4%2C4.8-0.2%2C6.6-1.7c1.8-1.5%2C2.9-3.8%2C2.9-6.2V194.8H453V414.4z%22%3E%3C%2Fpath%3E%0A%3Cpath%20fill%3D%22%23FCCF31%22%20class%3D%22primary-color%22%20d%3D%22M80.7%2C19.7L19.8%2C80.7V19.7H80.7z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M483.7%2C50.2c0%2C4.4-3.6%2C8-8%2C8h-15.8V74c0%2C4.4-3.6%2C8-8%2C8s-8-3.6-8-8V58.2h-15.8c-4.4%2C0-8-3.6-8-8s3.6-8%2C8-8h15.8V26.4%0A%09c0-4.4%2C3.6-8%2C8-8s8%2C3.6%2C8%2C8v15.8h15.8C480.1%2C42.2%2C483.7%2C45.8%2C483.7%2C50.2z%20M30.6%2C462.1c-5.9%2C0-10.8%2C4.8-10.8%2C10.8s4.8%2C10.8%2C10.8%2C10.8%0A%09s10.8-4.8%2C10.8-10.8S36.5%2C462.1%2C30.6%2C462.1z%20M228.4%2C26.7C213.9%2C26.7%2C202%2C38.5%2C202%2C53c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8%0A%09c0-5.7%2C4.7-10.4%2C10.4-10.4s10.4%2C4.7%2C10.4%2C10.4c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8C254.8%2C38.5%2C243%2C26.7%2C228.4%2C26.7z%22%3E%3C%2Fpath%3E%0A%3C%2Fsvg%3E) Fluent Python
Fluent Python这章主要讲字符串处理。
PyCon 2014 有个 slide 讲得非常好,比之前的 UniPain 更简单明了。放在 Dropbox/Journey/Resources/Python/character-encoding-and-unicode.pdf。它也有一个对应的 视频。
Character Issues
“字符串”(string)是一个由字符(character)组成的序列。但是重点是,字符(character)是指什么。
Unicode 标准的基本理念是,将标识一个字符是什么,从字符的字节表示(byte representation)中脱离出来。
- 字符的标识在 Unicode 标准中叫 Unicode code point。code point (码点?)是一个数字,范围在 0 到 1114111 (Unicode 6.3)。每个字符都有一个唯一的 Unicode code point。
- 字符的最终字节表示,取决于具体使用了什么编码。
Python 3 有两个表示字符串的基础类型,一个是 str,表示 Unicode 字符串;一个是 bytes,表示被编码(encode)过的字符串。
Byte Essentials
>>> cafe = bytes('café', encoding='utf_8')
>>> cafe
b'caf\xc3\xa9'
>>> cafe[0]
99
>>> cafe[:1]
b'c'
>>> cafe_arr = bytearray(cafe)
>>> cafe_arr
bytearray(b'caf\xc3\xa9')
>>> cafe_err[0]
99
>>> cafe_arr[-1:]
bytearray(b'\xa9')取下标和切片方面,有一些细节值得注意:
bytes和bytearray类型,取下标操作(cafe[0])返回的是一个 0~255 的整数;取切片(cafe[:1])时,返回的结果还是原类型,即bytes和bytearraystr类型比较特殊,取下标和取切片都是返回str类型str类型是 Python 的内置序列类型中,s[0] == s[:1]唯一成立的
对于 bytes 和 bytearray 被 print 的结果,里面即有 ASCII 字符也有 \x 的 16 进制表示。本来 bytes 表示的是一段字符序列,全部用 16 进制显示出来也不过份,但是这里应该是照顾了可读性,所以将 ASCII 字符打印出来了。规则如下:
- 如果字符是可打印的 ASCII 字符,以 ASCII 字符的形式显示
- 如果不是可打印的,但是是
\可转义的(如\n,\t),以这种形式显示 - 其他字符以
\xXX的 16 进制形式出现
str 类型的 print 结果均是显示字符的 Unicode 字符表示。比如 é 还是以 é 显示。但是这个 print 结果最终还是打到终端出来,所以终端的编码对它有影响。比如我的终端使用的是 UTF-8 编码,如果有一些 Unicode 字符没有对应的 UTF-8 编码,那么应该会展示成 \uXXXX 的形式。
实现了 buffer protocol 的类型有 bytes, bytearray, memoryview, array.array。
从一个实现了 buffer protocol 的对象初始化 bytes / bytearray 时总会有数据拷贝;而用同样的方式初始化 memoryview 时则不会有。
Structs and Memory Views
Structs 是用来做 Python 数据结构跟 C/C++ Struct 之间的相互转换的。书中的这个示例代码很好,用了 memoryview 去取前十个字节:
>>> import struct
>>> fmt = '<3s3sHH'
>>> with open('filter.gif', 'rb') as fp:
... img = memoryview(fp.read())
...
>>> header = img[:10]
>>> bytes(header)
b'GIF89a+\x02\xe6\x00'
>>> struct.unpack(fmt, header)
(b'GIF', b'89a', 555, 230)
>>> del header
>>> del imgBasic Encoders/Decoders
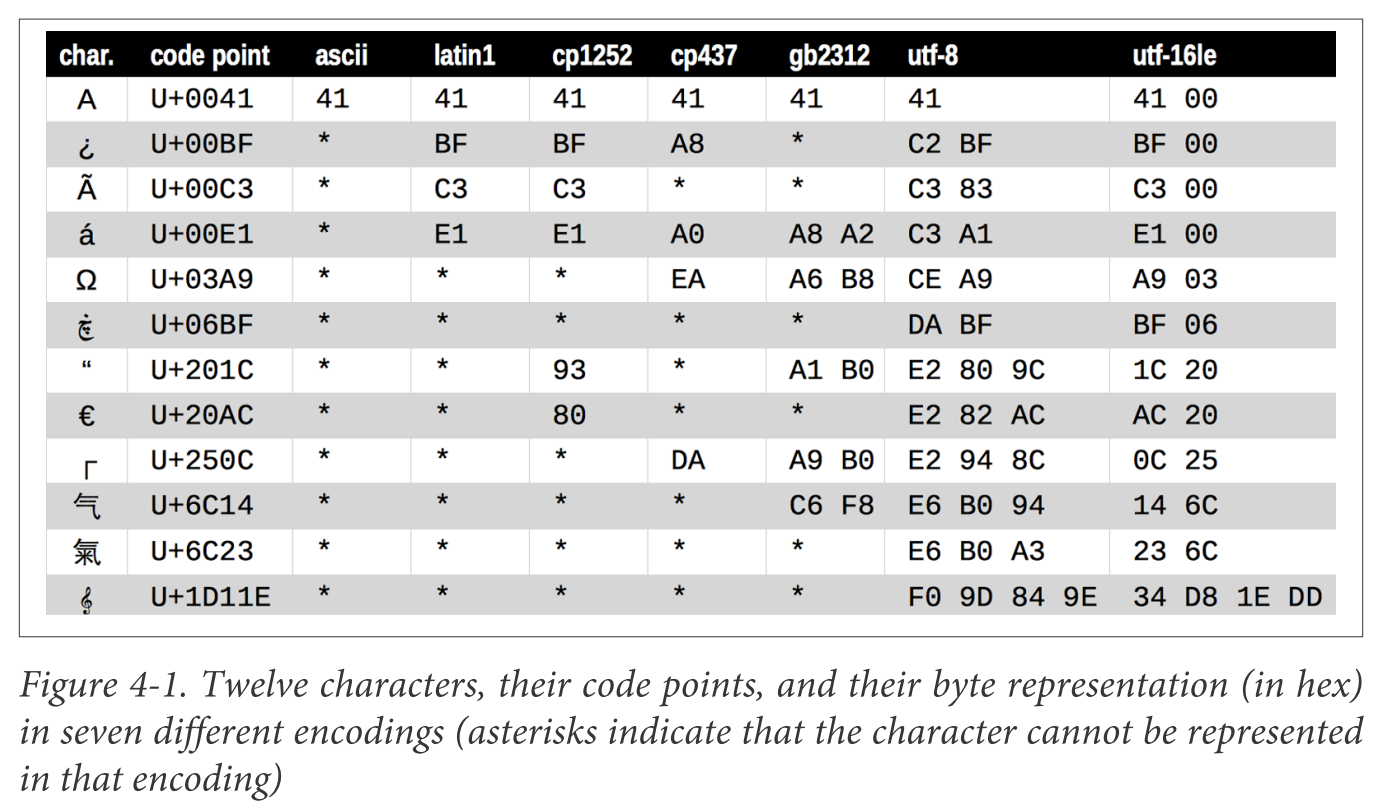
这个图可以看出,有些编码格式(如 ascii, gb2312)并不能编码全部的字符,这也是产生 UnicodeEncodeError / UnicodeDecodeError 的主要原因。Python 提供了一些参数,用来指定编解码失败时的行为:
>>> city = 'São Paulo'
>>> city.encode('utf_8')
b'S\xc3\xa3o Paulo'
>>> city.encode('utf_16')
b'\xff\xfeS\x00\xe3\x00o\x00 \x00P\x00a\x00u\x00l\x00o\x00'
>>> city.encode('iso8859_1')
b'S\xe3o Paulo'
>>> city.encode('cp437')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../lib/python3.4/encodings/cp437.py", line 12, in encode
return codecs.charmap_encode(input,errors,encoding_map)
UnicodeEncodeError: 'charmap' codec can't encode character '\xe3' in
position 1: character maps to <undefined>
>>> city.encode('cp437', errors='ignore')
b'So Paulo'
>>> city.encode('cp437', errors='replace')
b'S?o Paulo'
>>> city.encode('cp437', errors='xmlcharrefreplace')
b'São Paulo'而且这些行为还可以通过 `codecs.register_error` 来扩展。
How to Discover the Encoding of a Byte Sequence
怎样知道一串字节序列的编码呢?答案是:你没办法知道,除非有人告诉你。
但是不同的编码类型编出来的内容各有特点,所以可以大致推测出某段字节序列的编码。Chardet 库 做的就是这个事情。
BOM: A Useful Gremlin
UTF-16 编码在这上面的处理有点意思。它可以编成 Big Endian 也可以编成 Little Endian。对于 Big Endian,它编码出来的字节序列会在前面加上 ZERO WIDTH NO-BREAK SPACE (U+FEFF) \xFEFF;对于 Little Endian,会在前面加上 \xFFFE。但是 Unicode 码表中是没有 U+FFFE 的,所以程序遇到 UTF-16 字节序列时,可以看看前两个字节是 \xFEFF 还是 \xFFFE,来判断是大端小端。
Encoding Defaults: A Madhouse
这部分值得一看。说的是各种情况下 Python 用的默认字符编码。
结论是:
- 打开 (Linux API
open) 文件,或者 stdin / stdout / stderr 重定向到文件时,默认用的编码是locale.getpreferredencoding() - stdin / stdout / stderr 如果没有重定向到文件,且
PYTHONIOENCODING环境变量被指定时,默认编码使用环境变量定义的;如果环境变量未指定,则使用的编码继承自你的控制台(这里细节还没弄清楚) - bytes <=> str 的隐式转换,默认用的是
sys.getdefaultencoding()的编码。但是据说 Python 3 很少有这类隐式转换。Python 2 就有很多 - 如果传给
open函数的文件名参数是个 str,那么它会被使用sys.getfilesystemencoding()所表示的编码转成 bytes,再传给系统 API。如果文件名参数是个 bytes,则不会有转换,直接传给系统 API
终级结论是:不要依赖默认的编码类型,总是显式地指定它。
但是就算你搞定了 Unicode,还有可怕的 Unicode Normalization (正规化)问题等着你。
Normalizing Unicode for Saner Comparisons
Unicode 里面有个叫 组合字符(combining characters)的东西,它使得字符串的比较变得麻烦:
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1, s2
('café', 'café')
>>> len(s1), len(s2)
(4, 5)
>>> s1 == s2
False\u0301 是个变音符号,é 和 e\u0301 被称作 “canonical equivalents”。Unicode 规范中定义了 Unicode Normalization 来解决这个问题,Python 标准库中 `unicodedata.normalize` 是相应的实现。规范定义了四种 Normalization 的方法:NFC, NFD, NFKC, NFKD,每一种都可以解决字符串比较的问题:
>>> from unicodedata import normalize
>>> s1 = 'café' # composed "e" with acute accent
>>> s2 = 'cafe\u0301' # decomposed "e" and acute accent
>>> len(s1), len(s2)
(4, 5)
>>> len(normalize('NFC', s1)), len(normalize('NFC', s2))
(4, 4)
>>> len(normalize('NFD', s1)), len(normalize('NFD', s2))
(5, 5)
>>> normalize('NFC', s1) == normalize('NFC', s2)
TrueUnicode 的 文档 描述了这几种 Normalization Form:
| Form | Description |
|---|---|
| Normalization Form D (NFD) | Canonical Decomposition |
| Normalization Form C (NFC) | Canonical Decomposition, followed by Canonical Composition |
| Normalization Form KD (NFKD) | Compatibility Decomposition |
| Normalization Form KC (NFKC) | Compatibility Decomposition, followed by Canonical Composition |
简单的说,NFD 把字符串分解成字符和组合字符,而 NFC 把字符和组合字符组成成最短的同义字符串。大部分西文键盘敲出来的字符是 NFC 形式的,而且 NFC 是 W3C 推荐的正规化形式。
有些单个符号在 NFC 正规化后,会变成另外一个视觉上一致的符号。比如电阻的符号 Ω 会变成 Greek uppercase omega。
NFKD 和 NFKC 中的 K 表示 compatibility,因为他们会影响所谓的 compatibility characters。比如会把 ½ 转成 1/2,4² 会被转成 42。这两种形式可能会影响字符串的显示格式。一般的应用场景,是在搜索和建数据索引时。不是很理解这两种形式存在的意义是什么。
Case Folding
Case folding 做是的把字符串转成小写,并且做一些额外的转换。它的应用场景,是做大小写无关的字符串比较。有一部分字符会被转成视觉上一致的其他符号,如 µ 从 MICRO SIGN 转成 GREEK SMALL LETTER MU。
作者写了 一些代码 用来做字符串的规格化,而且还做了 IPython Notebook 页面,实在太良心了!
Sorting Unicode Text
Python 标准库 locale 对于地区相关的字符串排序做得并不好,依赖于 OS 实现和其他一些奇怪的条件。但是第三方库 PyUCA 是不错的解决方案。UCA 代表 Unicode Collation Algorithm,书里没细说它是个什么东西,有需要再细看。
The Unicode Database
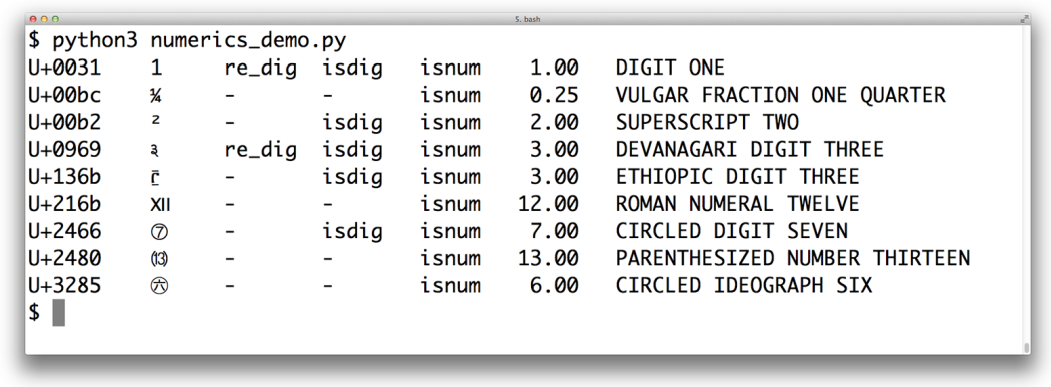
Unicode 数据库包罗万像,它不仅知道一个符号和它对应的含义,还知道这个符号是不是能打印的、是不是数字、是不是组合字符等。Python 标准库 unicodedata 可以解读这些信息,下面的图是用一段 Python 程序生成的,最后两列分别是 unicodedata.numeric(char) 和 unicodedata.name(char) 的结果:
Dual-Mode str and bytes APIs
在正则表达式中,str 跟 bytes 的表达式,在匹配时的行为不同。bytes 的正则表达式只会匹配 ASCII 字符,而 str 的会匹配各种 Unicode 字符。比如在 Tamil 语言 中表示数字 1729 的 ௧௭௨௯ 就可以被 str 正则表达式匹配出来。
在 OS 相关的函数中,很多都同时接受 str 或者 bytes 作为参数。因为 Linux 的文件系统并没有用 Unicode 存储信息,所以有一些文件名很可能是无法被 decode 成 unicode 的。Python 3 提供了 fsdecode 和 fsencode 函数,用来做文件名相关的字符串在 str 与 bytes 之间的相互转换。转换时用的编码是 sys.getfilesystemencoding(),并且用了 surrogateescape 来做错误处理(Linux 上)。
surrogateescape 挺有意思的。它使用了 Unicode 中的 Low Surrogate Area(U+DC00 到 U+DCFF)。这个区域仅限程序内部使用,即是说不作为数据在外部交换使用。fsdecode 时将不能 decode 成 unicode 的字节以 U+DCXX 的形式存起来,fsencode 时再把它解开:
>>> os.listdir('.')
['abc.txt', 'digits-of-π.txt']
>>> os.listdir(b'.')
[b'abc.txt', b'digits-of-\xcf\x80.txt']
>>> pi_name_bytes = os.listdir(b'.')[1]
>>> pi_name_str = pi_name_bytes.decode('ascii', 'surrogateescape')
>>> pi_name_str
'digits-of-\udccf\udc80.txt'
>>> pi_name_str.encode('ascii', 'surrogateescape')
b'digits-of-\xcf\x80.txt'留意上面的 \udccf 和 \udc80。
延伸阅读里面有一堆相关的好材料。