%22%20d%3D%22M425.8%2C392.9c-41.5-7.2-83.5-6.3-117.2%2C4.1l-50.5%2C25.5v-4.9h-6.9V416h-5.6%0A%09c-44.7-26.9-97.8-34.7-159.5-23.1v-28.7c0-29.4%2C23.8-53.2%2C53.2-53.2H222c14.2%2C0%2C26.3%2C8.8%2C31.2%2C21.2h6.9v13.3%0A%09c6.8-24.6%2C29.3-42.6%2C56.1-42.6h0c8.9%2C0%2C16.1-7.2%2C16.1-16.1V158.3c0-29.9%2C24.3-54.2%2C54.2-54.2h39.2V346L425.8%2C392.9z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M482.7%2C178.8H378.1c-4.4%2C0-8%2C3.6-8%2C8s3.6%2C8%2C8%2C8h39.6v188.6c-58.5-9.2-110-1-153.6%2C24.6V138.1%0A%09c42.5-27.9%2C94.1-37.1%2C153.6-27.2v45.9c0%2C4.4%2C3.6%2C8%2C8%2C8c0.8%2C0%2C1.6-0.1%2C2.3-0.3c0.7%2C0.2%2C1.5%2C0.3%2C2.3%2C0.3h43c4.4%2C0%2C8-3.6%2C8-8%0A%09s-3.6-8-8-8H469v-14.2c0-4.4-3.6-8-8-8s-8%2C3.6-8%2C8v14.2h-19.2v-44.6c0-3.9-2.7-7.2-6.5-7.9c-66.2-12.4-123.8-2.9-171.3%2C28.1%0A%09c-47.5-31-105.1-40.5-171.3-28.1c-3.8%2C0.7-6.5%2C4-6.5%2C7.9v22.4H50.3c-4.4%2C0-8%2C3.6-8%2C8v287.8c0%2C4.4%2C3.6%2C8%2C8%2C8h203.6%0A%09c0.6%2C0.1%2C1.2%2C0.2%2C1.7%2C0.2c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.6%2C0%2C1.2-0.1%2C1.7-0.2H461c4.4%2C0%2C8-3.6%2C8-8V194.8h13.8%0A%09c4.4%2C0%2C8-3.6%2C8-8S487.2%2C178.8%2C482.7%2C178.8z%20M58.3%2C142.5H78V366c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8V110.9c59.5-9.8%2C111.1-0.7%2C153.6%2C27.2V408%0A%09c-45.9-26.9-100.7-34.7-163.1-23c-4.3%2C0.8-7.2%2C5-6.4%2C9.3c0.8%2C4.3%2C5%2C7.2%2C9.3%2C6.4c52.1-9.8%2C98.4-5.2%2C137.9%2C13.6H58.3V142.5z%0A%09%20M453%2C414.4H286.4c39.5-18.8%2C85.8-23.4%2C137.9-13.6c2.3%2C0.4%2C4.8-0.2%2C6.6-1.7c1.8-1.5%2C2.9-3.8%2C2.9-6.2V194.8H453V414.4z%22%3E%3C%2Fpath%3E%0A%3Cpath%20fill%3D%22%23FCCF31%22%20class%3D%22primary-color%22%20d%3D%22M80.7%2C19.7L19.8%2C80.7V19.7H80.7z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M483.7%2C50.2c0%2C4.4-3.6%2C8-8%2C8h-15.8V74c0%2C4.4-3.6%2C8-8%2C8s-8-3.6-8-8V58.2h-15.8c-4.4%2C0-8-3.6-8-8s3.6-8%2C8-8h15.8V26.4%0A%09c0-4.4%2C3.6-8%2C8-8s8%2C3.6%2C8%2C8v15.8h15.8C480.1%2C42.2%2C483.7%2C45.8%2C483.7%2C50.2z%20M30.6%2C462.1c-5.9%2C0-10.8%2C4.8-10.8%2C10.8s4.8%2C10.8%2C10.8%2C10.8%0A%09s10.8-4.8%2C10.8-10.8S36.5%2C462.1%2C30.6%2C462.1z%20M228.4%2C26.7C213.9%2C26.7%2C202%2C38.5%2C202%2C53c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8%0A%09c0-5.7%2C4.7-10.4%2C10.4-10.4s10.4%2C4.7%2C10.4%2C10.4c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8C254.8%2C38.5%2C243%2C26.7%2C228.4%2C26.7z%22%3E%3C%2Fpath%3E%0A%3C%2Fsvg%3E) Fluent Python
Fluent Python这章讲的几个点:
- How Python evaluates decorator syntax
- How Python decides whether a variable is local
- Why closures exist and how they work
- What problem is solved by
nonlocal
看完之后可以实现:
- Implementing a well-behaved decorator
- Interesting decorators in the standard library
- Implementing a parameterized decorator
由于 decorator 这个词的命名,跟 设计模式 中的装饰器没什么关系,它与编译器领域中的概念相近。因此下面的笔记中我不用「装饰器」一词,而是直接用 decorator 来表达。
Decorators 101
decorator 就是个语法糖:
@decorate
def target():
print('running target()')效果等同于:
def target():
print('running target()')
target = decorate(target)When Python Executes Decorators
一个 decorated function(比如上一节中的 decorate),在 import time(也就是它所处的模块被加载时)就被执行了。比如:
def register(func):
print('running register(%s)' % func.__name__)
return func
@register
def f1():
print('running f1()')上面这段代码,被解释器加载时就会输出 running register(f1),在 f1 被调用时才输出 running f1()。
Decorator-Enhanced Strategy Pattern
怎样用 decorator 来更优雅地解决上一章中的问题,即用 decorator 来获得几个 promo 函数对象,以加入 promos 列表:
# old solution
promos = [fidelity_promo, bulk_item_promo, ...]
# new solution
promos = []
def promotion(promo_func):
promos.append(promo_func)
return promo_func
@promotion
def fidelity(order):
"""5% discount for customers with 1000 or more fidelity points"""
# ...
@promotion
def bulk_item(order):
"""10% discount for each LineItem with 20 or more units"""
# ...Variable Scope Rules
这节只讲了一个简单的规则。详细的规则可以参考 官方文档。这节的内容比较重要。
Python 使用的是块作用域。什么是一个 块 呢?
A block is a piece of Python program text that is executed as a unit. The following are blocks: a module, a function body, and a class definition.
所以函数体是一个块,但是 if 的分支语句不是一个块。
Python 解释器如何解释一个变量呢?它会先从本地块开始找,如果找不到,就一层一层往更外面的块作用域找,最后找到全局作用域。如果还没有,就会抛出 NameError。如果一个函数体里面定义了一个变量,但是在定义它之前就使用了,那会抛出一个 UnboundLocalError:
a = 2
def f1():
print(a) # 会抛 UnboundLocalError
a = 3a 被解释器认为是当前函数作用域中的变量,但是它还没被定义,所以会抛 UnboundLocalError。
有两个关键字可以打破这个解析变量名的过程:global 和 nonlocal。如果你给一个变量声明了 global,那解释器会直接在全局块找这个变量;如果声明了 nonlocal,那解释器就不会在这个声明所在的块里面去找变量,而是直接在最靠近的块去找:
a = 2
def f1():
global a # a 此时指全局块中的 a
print(a) # 这里不会抛异常,会输出 2
a = 3 # 修改的是全局的 anonlocal 的例子在下一节的 closure 中会讲。
Closures
书里面用了两个例子对比,来说明什么是 closure。
如果你需要实现一个动态计算平均数的功能,你会怎样实现呢?效果如下:
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0即是,你需要在 avg 这个计算过程以外,有一个地方存放之前的数据(在这个例子中的 10, 11, 12)。
第一种实现:用 callable class instance 来保存中间变量 series,中间数据随着 avg 变量的存在而存在:
class Averager():
def __init__(self):
self.series = []
def __call__(self, new_value):
self.series.append(new_value)
total = sum(self.series)
return total/len(self.series)
>>> avg = Averager()
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0第二种实现,用 closure:
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
>>> avg = make_averager()
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0closure 这个例子很有意思,它把中间数据 series 放在计算过程 averager 的外面一层的函数中。而 Python 是一门动态语言,使用了引用计数来做垃圾回收;虽然 make_average 执行完了,但是只要 averager 函数对象和 series 变量可以被引用到,那么它们就不会被回收。
所以什么是 closure 呢?一图胜千言:
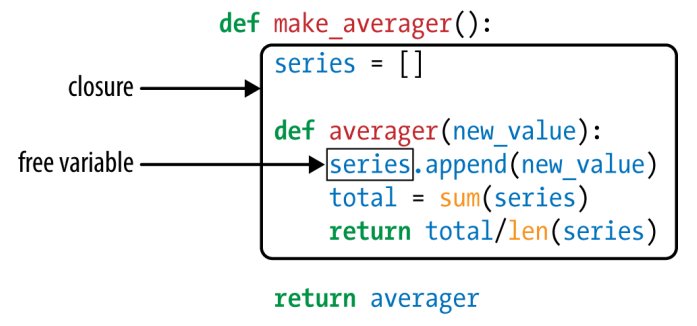
To summarize: a closure is a function that retains the bindings of the free variables that exist when the function is defined, so that they can be used later when the function is invoked and the defining scope is no longer available.
free variables 是那些它自己的 local scope 已经被销毁了的变量。上面的 series 可以通过 avg.__code__.co_freevars, avg.__closure__ 访问到。
The nonlocal Declaration
上面已经讲到 nonlocal 关键字的含义。那么什么时候需要用它?
def make_averager():
count = 0
total = 0
def averager(new_value):
count += 1
total += new_value
return total / count
return averager
>>> avg = make_averager()
>>> avg(10)
Traceback (most recent call last):
...
UnboundLocalError: local variable 'count' referenced before assignment
>>>这里为什么会抛异常呢?原因是 count, total 都是整数,是不可变类型。意味着它们没有实现 __iadd__ 函数,于是 count += 1 等同于 count = count + 1(参考),于是在 averager 函数块里又定义了一个新变量 count。但是 count + 1 又提前使用了这个变量,于是报 UnboundLocalError。
解决办法是使用 nonlocal:
def make_averager():
count = 0
total = 0
def averager(new_value):
nonlocal count, total
count += 1
total += new_value
return total / count
return averager但是这个关键字只在 Python 3 才有。Python 2 的话需要一些 walkaround,比如在上层块里面定义一个词典(可变类型)供下层块使用。
Implementing a Simple Decorator
这节定义了一个计算函数运行时间的 decorator,然后具体使用上了。比较简单。但是有一个问题是,被 decorated 的函数,它的 __name__, __doc__ 等变量也被替换了,于是会有:
@clock
def snooze(seconds):
time.sleep(seconds)
>>> snooze.__name__
'clocked'这个时候可以用标准库的 functools.wraps decorator 来解决,它会把被装饰的函数的几个属性拷过去:
def clock(func):
@functools.wraps(func)
def clocked(*args, **kwargs):
# ...
@clock
def snooze(seconds):
time.sleep(seconds)
>>> snooze.__name__
'snooze'Decorators in the Standard Library
Memoization with functools.lru_cache
第一个介绍的是 functools.lru_cache。这是一个非常方便的装饰器,对于一些运行缓慢的函数,可以把运行结果缓存起来。比如下面的 fibonacci 函数:
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-2) + fibonacci(n-1)
if__name__=='__main__':
print(fibonacci(6))如果不对 fibonacci 的计算结果做缓存,这个计算是非常慢的,因为有很多不必要的重复计算(fibonacci(4) 就算了 2 次)。
给 fibonacci 加了 @functools.lru_cache() 装饰器,可以很高效率地提高速度,减少了不必要的计算。
lru_cache 缓存的依据是函数参数,默认缓存 128 个结果。同时注意它是个返回 decorator 函数的函数,所以你在加 @functools.lru_cache() 时,不能漏掉括号。
Generic Functions with Single Dispatch
singledispatch 针对的场景是,一些需要理解参数类型的函数过程。它可以实现一个函数针对不同参数有不同的行为:
>>> fun("test.", verbose=True)
Let me just say, test.
>>> fun(42, verbose=True)
Strength in numbers, eh? 42
>>> fun(['spam', 'spam', 'eggs', 'spam'], verbose=True)
Enumerate this:
0 spam
1 spam
2 eggs
3 spam
>>> fun(None)
Nothing.
>>> fun(1.23)
0.615singledispatch 可以你不需要写一堆 if/else 来判断类型走分支。具体的实现方式看文档就可以了,这里不描述。
这种场景看起来跟面向对向中的接口(Interface)类似,为不同的类型定义一个共同的接口。Python 也可以有类似的实现,但是 singledispatch 有一些优势:
- 对于一些内置类型,你不好去给它实现接口函数。比如在 int 类型中实现一个新的方法,这是不好的实践;如果继承一个新类出来,又把问题搞复杂了。
- Python 提倡 duck typing,即不关心具体的类型而关注协议(比如内置的
len,sort函数),用singledispatch可以实现这种 generic function(比如前面代码例子中的fun),而且不需要像内置函数一样要求在各个类中实现 dunder 函数(比如__len__)。
扩展阅读:
- PEP 443 -- Single-dispatch generic functions: 讲了这个设计的由来,以及一些相近的实现(没太看明白)
- What single-dispatch generic functions mean for you: 它讲述了一些具体的应用场景(UI widgets, serialization formats and protocol handlers),以及怎样在 class method 中使用
singledispatch。