%22%20d%3D%22M425.8%2C392.9c-41.5-7.2-83.5-6.3-117.2%2C4.1l-50.5%2C25.5v-4.9h-6.9V416h-5.6%0A%09c-44.7-26.9-97.8-34.7-159.5-23.1v-28.7c0-29.4%2C23.8-53.2%2C53.2-53.2H222c14.2%2C0%2C26.3%2C8.8%2C31.2%2C21.2h6.9v13.3%0A%09c6.8-24.6%2C29.3-42.6%2C56.1-42.6h0c8.9%2C0%2C16.1-7.2%2C16.1-16.1V158.3c0-29.9%2C24.3-54.2%2C54.2-54.2h39.2V346L425.8%2C392.9z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M482.7%2C178.8H378.1c-4.4%2C0-8%2C3.6-8%2C8s3.6%2C8%2C8%2C8h39.6v188.6c-58.5-9.2-110-1-153.6%2C24.6V138.1%0A%09c42.5-27.9%2C94.1-37.1%2C153.6-27.2v45.9c0%2C4.4%2C3.6%2C8%2C8%2C8c0.8%2C0%2C1.6-0.1%2C2.3-0.3c0.7%2C0.2%2C1.5%2C0.3%2C2.3%2C0.3h43c4.4%2C0%2C8-3.6%2C8-8%0A%09s-3.6-8-8-8H469v-14.2c0-4.4-3.6-8-8-8s-8%2C3.6-8%2C8v14.2h-19.2v-44.6c0-3.9-2.7-7.2-6.5-7.9c-66.2-12.4-123.8-2.9-171.3%2C28.1%0A%09c-47.5-31-105.1-40.5-171.3-28.1c-3.8%2C0.7-6.5%2C4-6.5%2C7.9v22.4H50.3c-4.4%2C0-8%2C3.6-8%2C8v287.8c0%2C4.4%2C3.6%2C8%2C8%2C8h203.6%0A%09c0.6%2C0.1%2C1.2%2C0.2%2C1.7%2C0.2c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.1%2C0%2C0.2%2C0%2C0.3%2C0c0.6%2C0%2C1.2-0.1%2C1.7-0.2H461c4.4%2C0%2C8-3.6%2C8-8V194.8h13.8%0A%09c4.4%2C0%2C8-3.6%2C8-8S487.2%2C178.8%2C482.7%2C178.8z%20M58.3%2C142.5H78V366c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8V110.9c59.5-9.8%2C111.1-0.7%2C153.6%2C27.2V408%0A%09c-45.9-26.9-100.7-34.7-163.1-23c-4.3%2C0.8-7.2%2C5-6.4%2C9.3c0.8%2C4.3%2C5%2C7.2%2C9.3%2C6.4c52.1-9.8%2C98.4-5.2%2C137.9%2C13.6H58.3V142.5z%0A%09%20M453%2C414.4H286.4c39.5-18.8%2C85.8-23.4%2C137.9-13.6c2.3%2C0.4%2C4.8-0.2%2C6.6-1.7c1.8-1.5%2C2.9-3.8%2C2.9-6.2V194.8H453V414.4z%22%3E%3C%2Fpath%3E%0A%3Cpath%20fill%3D%22%23FCCF31%22%20class%3D%22primary-color%22%20d%3D%22M80.7%2C19.7L19.8%2C80.7V19.7H80.7z%22%3E%3C%2Fpath%3E%0A%3Cpath%20d%3D%22M483.7%2C50.2c0%2C4.4-3.6%2C8-8%2C8h-15.8V74c0%2C4.4-3.6%2C8-8%2C8s-8-3.6-8-8V58.2h-15.8c-4.4%2C0-8-3.6-8-8s3.6-8%2C8-8h15.8V26.4%0A%09c0-4.4%2C3.6-8%2C8-8s8%2C3.6%2C8%2C8v15.8h15.8C480.1%2C42.2%2C483.7%2C45.8%2C483.7%2C50.2z%20M30.6%2C462.1c-5.9%2C0-10.8%2C4.8-10.8%2C10.8s4.8%2C10.8%2C10.8%2C10.8%0A%09s10.8-4.8%2C10.8-10.8S36.5%2C462.1%2C30.6%2C462.1z%20M228.4%2C26.7C213.9%2C26.7%2C202%2C38.5%2C202%2C53c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8%0A%09c0-5.7%2C4.7-10.4%2C10.4-10.4s10.4%2C4.7%2C10.4%2C10.4c0%2C4.4%2C3.6%2C8%2C8%2C8s8-3.6%2C8-8C254.8%2C38.5%2C243%2C26.7%2C228.4%2C26.7z%22%3E%3C%2Fpath%3E%0A%3C%2Fsvg%3E) Fluent Python
Fluent Python这章主要构建了一个教学 Vector 类,对 Python 的数据模型做了更深入的探讨。每一节的内容都比较相关,因此我不再按章节写笔记,而是总的写在一起。
Slicing
def __getitem__(self, index):
cls = type(self)
if isinstance(index, slice):
return cls(self._components[index])
elif isinstance(index, numbers.Integral):
return self._components[index]
else:
msg = '{cls.__name__} indices must be integers'
raise TypeError(msg.format(cls=cls))调用 v1[0] 时传入的是整数,调用 v1[0:3] 这种传入的是 slice 对象。方括号中的 0:3 可以说是一种 slice literal。
S.indices(len) -> (start, stop, stride) 这个函数非常实用,它可以把 negative index 转成正的,方便你做一些操作:
>>> slice(None, 10, 2).indices(5)
(0, 5, 2)
>>> slice(-3, None, None).indices(5)
(2, 5, 1)Dynamic Attribute Access
Python 的 instance attribute 存在类的 __dict__ 中,class attributes 存在类的 __class__ 中。当你访问某个 attributes 时,Python 会先从这两个地方找变量,如果没找到会调用 __getitem__ 函数。
所以要实现 Dynamic Attribute Access,你要实现 __getitem__ 函数,同时最好实现配套的 __setitem__ 函数。
Hashing
如果你想把一个类实例作为 set dict 的 key,你需要让他不可变
,同时保证它的 hash() 值在整个生命周期保持不变。
一般的实现方式是,将类中的 attributes 先 hash 再异或,对于多个 attributes 的情况,map reduce 很适合这种场景:
def __hash__(self):
hashes = map(hash, self._components)
return functools.reduce(operator.xor, hashes, 0)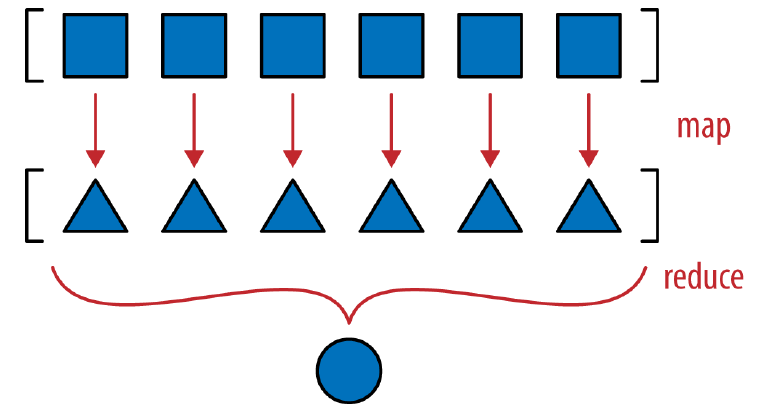
Python 3 vs Python 2
Python 3 把很多内置函数从生成一个 list,变成返回一个 iterator,比如 map zip 等。这对内存和性能都有很大帮助。
The Awesome zip
zip 内置函数可以把多个 iterable 像拉链一样重组:
>>> list(zip(range(3), 'ABC'))
[(0, 'A'), (1, 'B'), (2, 'C')]但是它在最短的 iterable 消耗完就停止了。你可以用 itertools.zip_longest 提供默认值,使最长的 iterable 也可以被 zip:
>>> list(zip(range(3), 'ABCD'))
[(0, 'A'), (1, 'B'), (2, 'C')]
>>> from itertools import zip_longest
>>> list(zip_longest(range(3), 'ABCD', fillvalue=-1))
[(0, 'A'), (1, 'B'), (2, 'C'), (-1, 'D')]The Search for a Pythonic Sum
Future Reading 里面有一个值得一看的故事,讲述大家在讨论 Pythonic way to sum n-th list element? 的故事。当时 Python 并没有 sum 内置函数,于是一些有 OOP 经验的人使用了 functools.reduce 和 lambda 来写:
>>> my_list = [[1, 2, 3], [40, 50, 60], [9, 8, 7]]
>>> import functools
>>> functools.reduce(lambda a, b: a+b, [sub[1] for sub in my_list])
60但是这实在是太丑了,即有 lambda 又有 reduce,还有 list comprehension。于是大家写出了优化版本:
>>> functools.reduce(lambda a, b: a + b[1], my_list, 0)
60
>>> functools.reduce(operator.add, [sub[1] for sub in my_list], 0)
60但是 reduce 会使得求和 (sum) 的意图不明。有人觉得这样写还不如直接:
>>> t = 0
>>> for sub in my_list:
... total += sub[1]
>>> t
60对此有两段评论说得好:
I like Evan Simpson’s code but I also like David Eppstein’s comment on it:If you want the sum of a list of items, you should write it in a way that looks like “the sum of a list of items”, not in a way that looks like “loop over these items, maintain another variable t, perform a sequence of additions”. Why do we have high level languages if not to express our intentions at a higher level and let the language worry about what low-level operations are needed to implement it?Then Alex Martelli comes back to suggest:“The sum” is so frequently needed that I wouldn’t mind at all if Python singled it out as a built-in. But “reduce(operator.add, …” just isn’t a great way to express it, in my opinion (and yet as an old APL’er, and FP-liker, I should like it—but I don’t).
最终导致 3 个月后 Python 添加了内置的 sum 函数。于是可以:
>>> sum([sub[1] for sub in my_list])
60这也说明了为何 Python 3 把 map reduce 放到 functools 里面而不放在内置函数中。它们缺乏表达能力。
Protocol v.s. Interface
Python 里面的 dunder 函数,只能算做一种 protocol,而非 interface。protocol 像是一种不太强的约定,而 interface 是一种强的约定。比如我实现了 __getitem__ 来取下标,但是如果对于我的类,slicing 并没有意义,那我可以不实现对 slice 的处理。而 interface 表示你必须实现它约定的一系列函数。