Golang 的依赖注入。
什么是依赖注入
软件工程中的 object 常常有多层级的依赖关系,比如:
BookController依赖BookService依赖BookDao依赖redis.Client
等等。依赖注入的理念是,与其每个 object 去管理自己依赖的 object,不如让一个外部系统来管理。这个系统知晓你的依赖关系,并在你需要的地方给你对的 object。比如使用 uber-go/dig 的一个例子:
// TransifyService 依赖于 redis
func NewTransifyService(redis *redis.Client) *TransifyService {
// ...
}}
// 将 TransifyService 及 redis.Client 的生成方法(New 函数)提供给 container
var AdminContainer *dig.Container
func init() {
Container = dig.New()
Container.Provide(cache.NewRedisClient)
Container.Provide(transify.NewTransifyService)
}
// 你有某处理函数依赖于 TransifyService,可以直接找 container 要,它会给你一个初始化好的实例。
func process() {
var service *transify.TransifyService
err := Container.Invoke(func(s *transify.TransifyService) {
service = s
})
// ...
}这样使得你不需要:
- 使用大量的全局变量,比如弄一个全局的
TransifyService实例 - 在各处代码去做复杂的依赖初始化,比如在
process()函数中去初始化一个TransifyService实例;这又要求你要初始化一个redis.Client
Go 中的流行实现
目前 google/wire 及 uber-go/dig 是主流的实现。
- wire 是在编译期,把对象初始化的函数都生成好,相对来讲性能更高及可靠;缺点是相对麻烦。而且一种类型的依赖可能会同时存在多个实例,视你的具体情况,这可能是个优点也可能是缺点
- dig 是在运行期通过反射来获得对象。性能相对差些。一种类型的依赖,在内存中应该只存在一个实例,类似全局变量
目前看 wire 的 Github star 三倍于 dig。不确定使用哪个更好。
Wire 定义了两个概念:
- Provider:即
NewXXX()函数 - Injector:即
InitXXX()函数
对于传参初始化对象的支持不足
比如使用 wire 的这样一段代码:
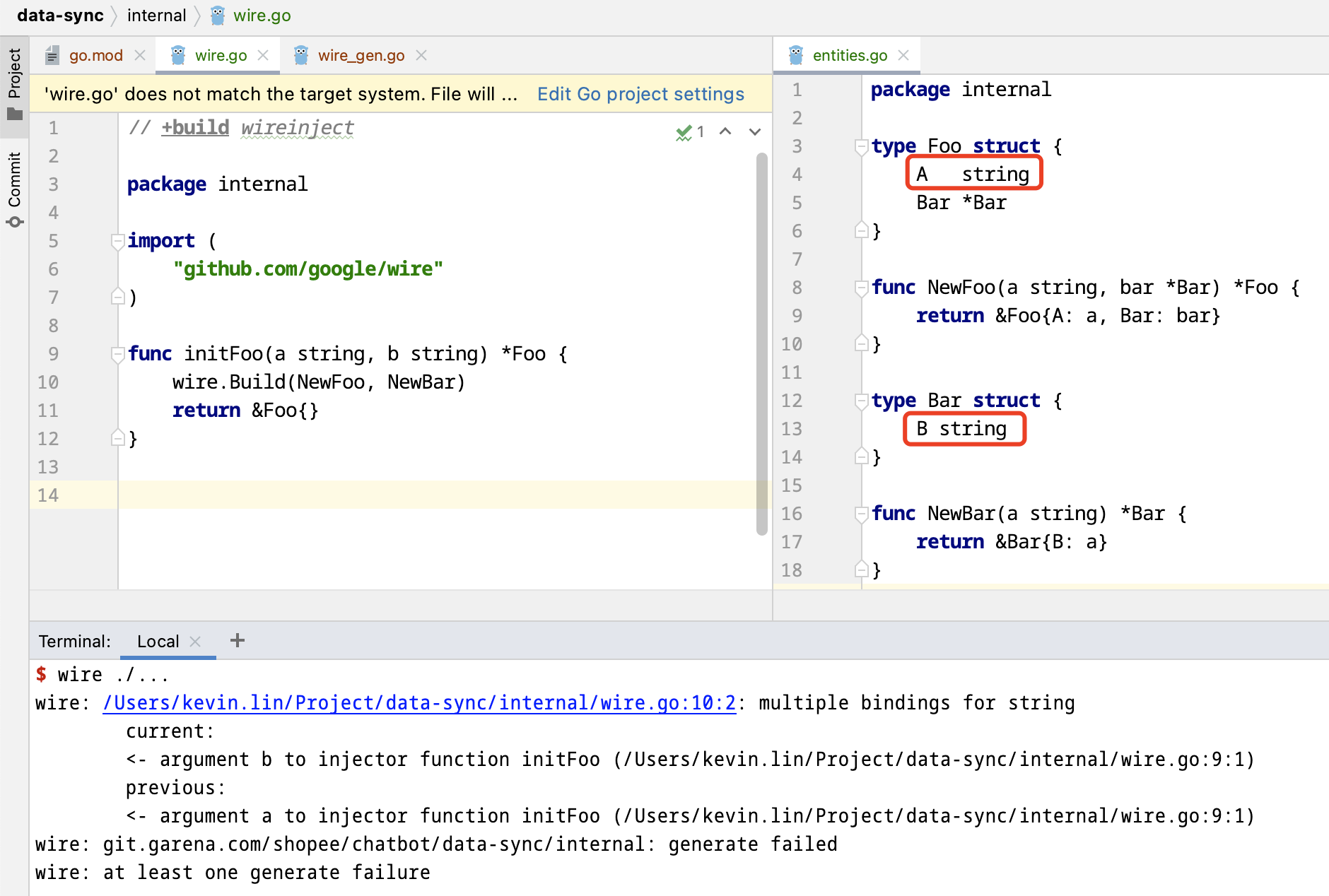
Foo 依赖于 Bar;Foo 及 Bar 中各有一个 string 字段。如果你期望 initFoo 中可以分别指定这两个 string 的值,那会是做不到的:
- wire 并不关心
initFoo中参数的名字(a,b),它只关心它的类型是string - 如果你只提供一个
string参数,那么FooBar的 string 字段都会被赋上这个参数的值 - 如果
Bar.B换成int型,在initFoo的参数中也加上一个int型参数,那么Bar.B也会被此参数赋值
这意味着:
- 如果你想传参给 provider,指导它如何初始化具体对象,那么你最好定义一个单独的类(比如
RedisOption),避免使用内置类型; - 更好的方式可能是在 provider 中读取固定的配置。不然会导致 Injector 每层都需要传递这个参数类,非常繁琐