pprof 开启 CPU profile 时,会每秒中断 100 次(即每 10ms 中断一次),来获取当前运行的函数和其调用栈帧(stack frame)。调用栈最多会纪录 100 层。递归调用自己时,调用栈中出现的多次同名函数也一样会被统计。
在思考 CPU profiling 结果时,需要记住它的核心是:在程序运行时频繁中断,采集当时的调用栈来做分析。
pprof 的 report 有两种方式可以看,一种是命令行,一种是 web(SVG)。这两种都值得理解一下。
命令行方式
$ go tool pprof havlak1 havlak1.prof
Welcome to pprof! For help, type 'help'.
(pprof) top10
Total: 2525 samples
298 11.8% 11.8% 345 13.7% runtime.mapaccess1_fast64
268 10.6% 22.4% 2124 84.1% main.FindLoops
251 9.9% 32.4% 451 17.9% scanblock
178 7.0% 39.4% 351 13.9% hash_insert
131 5.2% 44.6% 158 6.3% sweepspan
119 4.7% 49.3% 350 13.9% main.DFS
96 3.8% 53.1% 98 3.9% flushptrbuf
95 3.8% 56.9% 95 3.8% runtime.aeshash64
95 3.8% 60.6% 101 4.0% runtime.settype_flush
88 3.5% 64.1% 988 39.1% runtime.mallocgc表示一共有 2525 个采样。以第二行的 main.FindLoops 为例,各列分别指该函数在采样时:
- 正在执行此函数的次数;采样时一共有 267 次,程序正在运行该函数(不包括它所调用的其他函数)
- 占总次数的比例
- 与上面的行累计起来的比例
- 正在执行此函数,或者该函数在等待它调用的函数返回的次数;采样时一共有 2124 次,程序正在运行该函数(此时该函数在调用栈顶部),或者程序正在运行其调用的函数(此时该函数在调用栈的中间)
- 这个函数出现在全部采样的调用栈中的比例
1、2 列被称为 flat;4、5 列被称为 cum。
如果你只想按第四、五列排序,可以用 -cum 参数:
(pprof) top5 -cum
Total: 2525 samples
0 0.0% 0.0% 2144 84.9% gosched0
0 0.0% 0.0% 2144 84.9% main.main
0 0.0% 0.0% 2144 84.9% runtime.main
0 0.0% 0.0% 2124 84.1% main.FindHavlakLoops
268 10.6% 10.6% 2124 84.1% main.FindLoops正常来讲顶部的几个函数应该趋近于 100%。但是由于这个程序中有递归调用,且调用层级超过 100 层,导致调用栈被 truncate 而无法反映出完全真实的情况。
Web 方式
Web 方式会使用 SVG 展示一个图表。下面的图表样式比较旧了,但核心的理念是一样的:
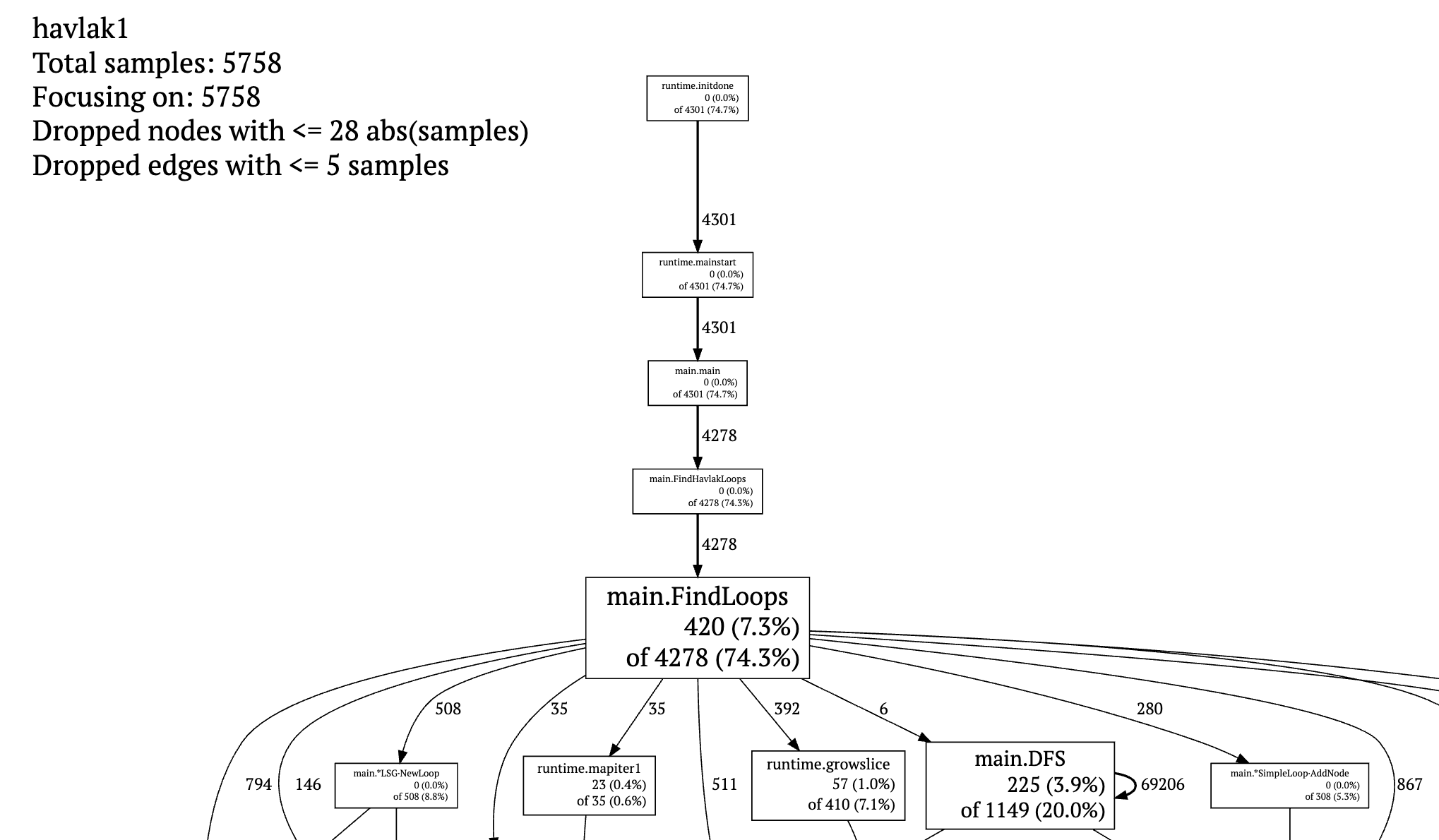
以 main.FindLoops 为例:
- 有 420 个采样时程序正在运行此函数(不包括它调用的其他函数);7.3% 表示占全部采样数的比例(420 / 5758)。字体的大小体现的是这个比例,也就是说,框越大,CPU 耗费在这个函数本身的时间越多
- 有 4278 个采样时,该函数出现在调用栈中;74.3% 是占全部采样数的比例(4278 / 5758)
- 箭头表示调用次数;越粗表示调用次数越多
值得注意的是,main.DFS 有一个指向自己的箭头,一共有 6 万多次,超过了采样数量 5758。这是因为它存在递归调用自身,而每一次递归调用会使调用栈中有多个 main.DFS,这些都会纳入统计。但新版的图表中,似乎仅把它当作一次了。
目前(2021 年 11 月)的图表样式及其解读,可以看 这里。
火焰图
pprof 还可以生成火焰图。火焰图是 Brendan Gregg 弄的一种图表:
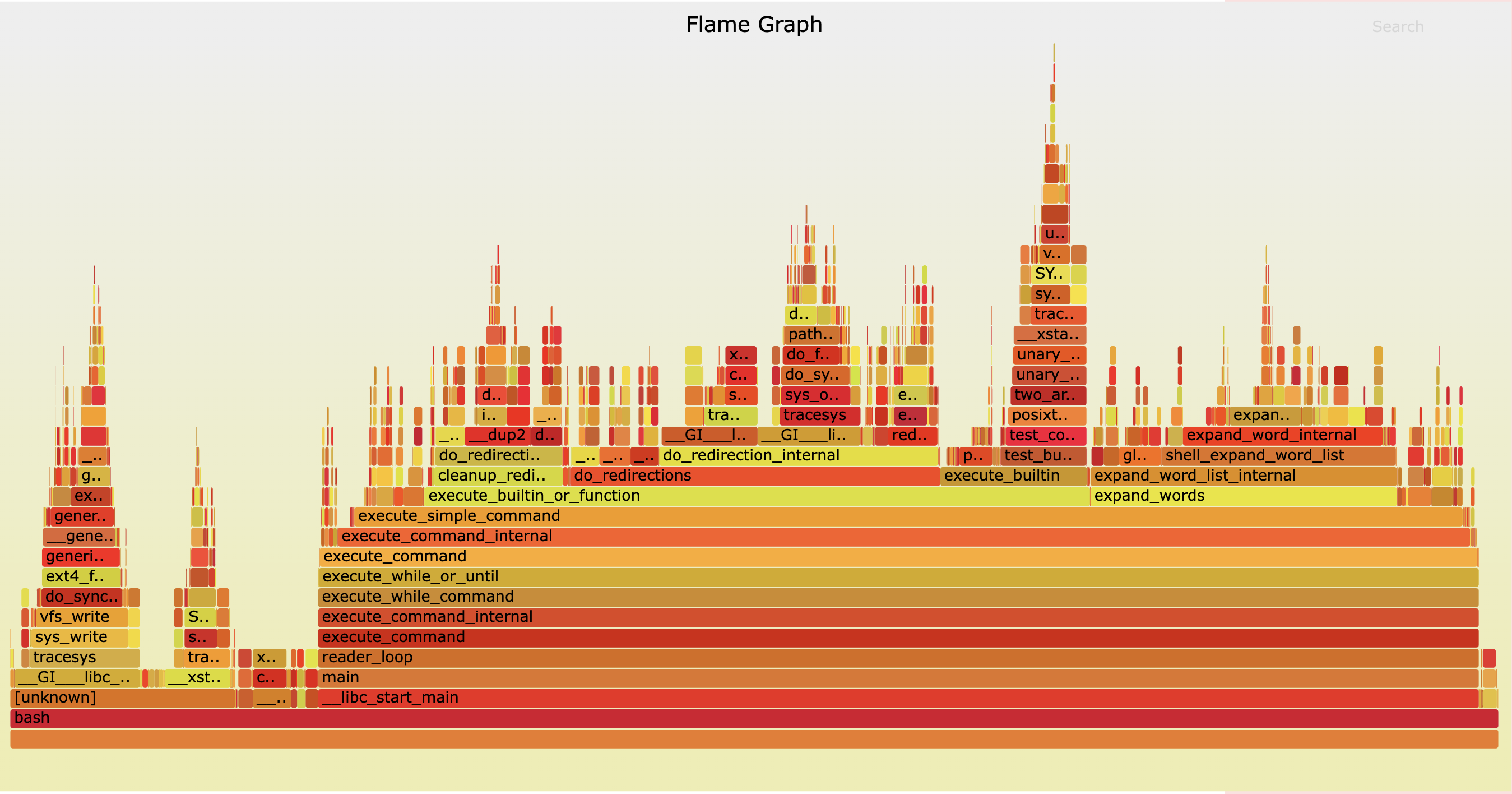
如何解读可以看 这里。核心是:
- 颜色不重要,是随机的暖色
- 条越长,表示这个函数在采样中出现得更多
- 条的左右顺序跟程序执行无关,是字母序的