这里的内容主要来自 HTTP: The Definitive Guide 第 11 章。
网站通常有识别请求用户信息的需求,用来:
- 根据用户的设备显示不同的样式
- 获得用户自定义的数据,比如论坛的发帖
- 做推荐系统等
常用的识别方式:
- HTTP headers that carry information about user identity
- Client IP address tracking, to identify users by their IP addresses
- User login, using authentication to identify users
- Fat URLs, a technique for embedding identity in URLs
- Cookies, a powerful but efficient technique for maintaining persistent identity
HTTP headers
| Header name | Header type | Description ! |
|---|---|---|
| From | Request | User’s email address |
| User-Agent | Request | User’s browser software |
| Referer | Request | Page user came from by following link |
| Authorization | Request | Username and password (discussed later) |
| Client-ip | Extension (Request) | Client’s IP address (discussed later) |
| X-Forwarded-For | Extension (Request) | Client’s IP address (discussed later) |
| Cookie | Extension (Request) | Server-generated ID label (discussed later) |
其中 From 已经不再使用。User-Agent 及 Referer 仍然被经常使用。
Client IP
非常早期的互联网应用会以 IP 来识别用户。但是后来慢慢废弃了,因为:
- 客户端 IP 只能描述对应的电脑,而不是电脑上的用户;一台电脑可以有多个用户
- 很多 ISP 分配给用户使用的是动态 IP
- 很多用户会用路由器等 NAT 设备,服务端无法知道 NAT 背后的具体设备是什么
- 如果用户的请求经 HTTP 代理,那么服务端看到的是 HTTP 代理的 IP;虽然部分代理会把用户的 IP 以
X-Forwarded-For头带上,但不是所有代理都会
User Login (Basic Authentication)
流程如下:
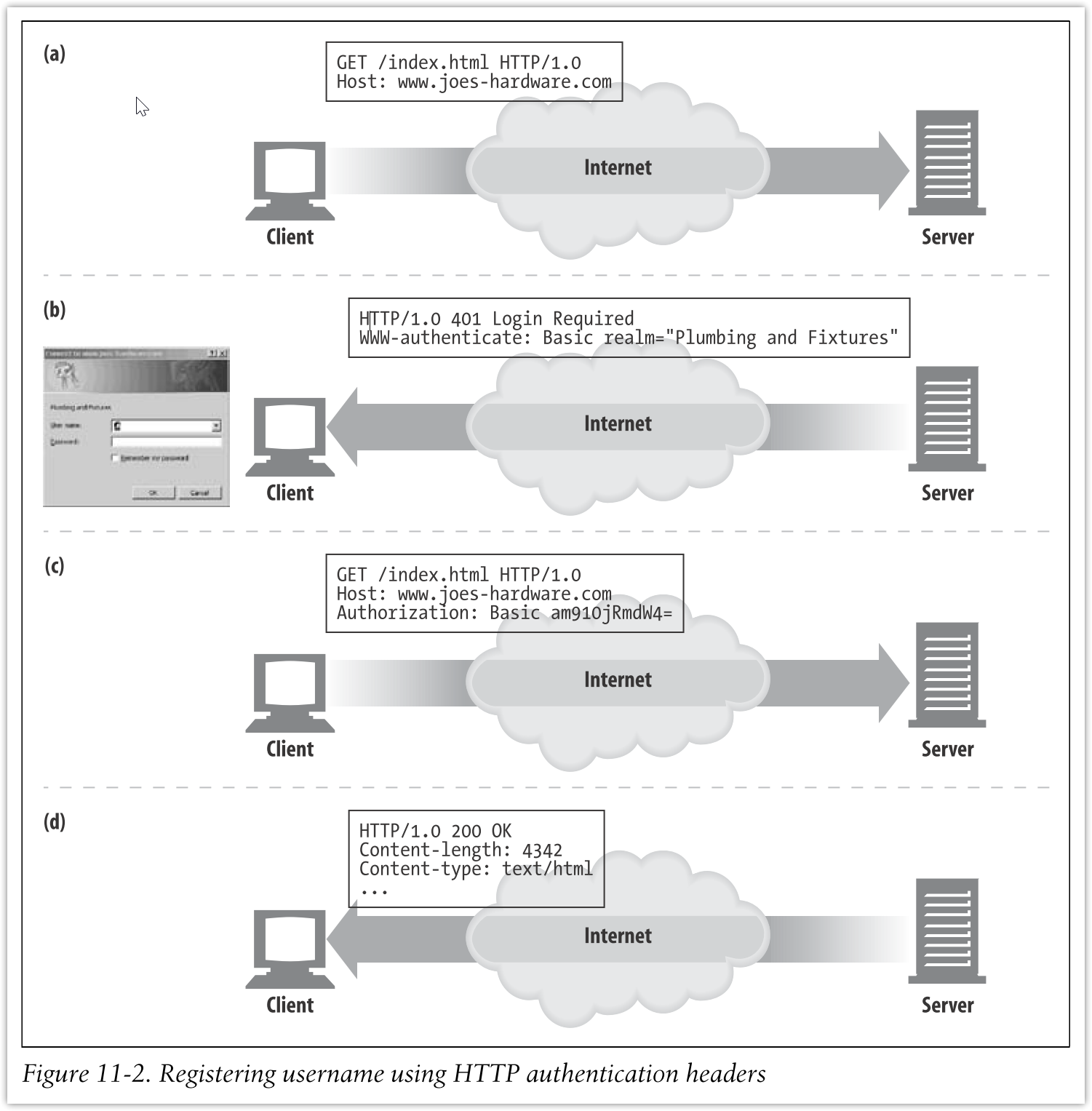
主流的互联网应用不再使用它:
- 如果不走 HTTPS,那用户的密码是明文暴露的
- 密码的过期策略依赖于浏览器实现
- 登录方式不够友好
Fat URLs
即每个链接中都带有用户 ID。如早期亚马逊的链接,留意其中的 002-1145265-8016838:
<a href="/exec/obidos/tg/browse/-/229220/ref=gr_gifts/002-1145265-8016838">All
Gifts</a><br>
<a href="/exec/obidos/wishlist/ref=gr_pl1_/002-1145265-8016838">Wish List</a><br>
<a href="http://s1.amazon.com/exec/varzea/tg/armed-forces/-//ref=gr_af_/002-1145265-
8016838">Salute Our Troops</a><br>
<a href="/exec/obidos/tg/browse/-/749188/ref=gr_p4_/002-1145265-8016838">Free
Shipping</a><br>这种方式的问题:
- URL 丑陋
- 不停重写 URL 需要耗费大量性能
- 如果用户不小心用了不带 user ID 的 URL,追踪就停止了
- 无法分享 URL,否则会引起混乱
- 无法利用缓存,因为每个用户的 URL 都不一样
Cookies
目前的主流方式。在 HTTP: Cookie 中单独描述。