Java 标准库中的 HashMap 实现。
模型
HashMap 有 初始容量(initial capacity) 及 负载因子(load factor)。这两个参数最影响性能。默认的初始容量为 16,负载因子为 0.75。向 HashMap 插入数据后,如果数据的数量达到阈值(容量 × 负载因子),HashMap 会做 rehashing,即把容量扩大一倍,并将数据重新 hash 到 bucket 上。
Bucket 是下图中的 16 个格子,里面装了 hash 到这个桶的数据。Bucket 的数量即当前的容量。
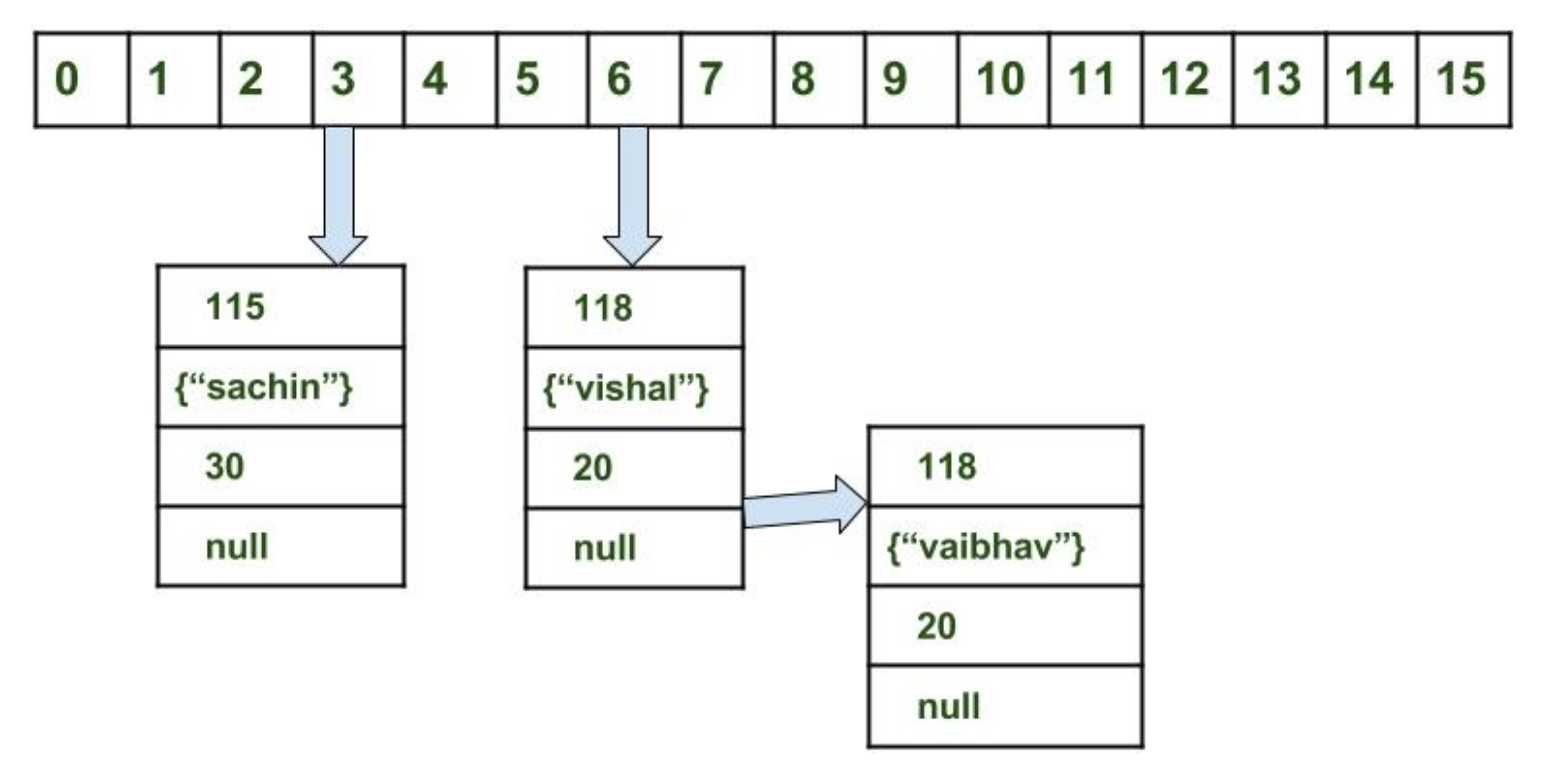
每次一个新数据(key 表示)插入时,它的 hashCode() 会被调用,再对 HashMap 容量(n 表示)取余后,落入具体的 bucket 中:
key.hashCode() % n每个数据有这几个属性(对应上图):
- int 型 hash 值
- Key
- Value
- 同 hash 值的下一个数据的指针
冲突时的处理
不同的 key 可能有同样的 hashCode()。此时它们会落入同个桶内。JDK 8 之前用链表来连接这些对象;但出于安全考虑(攻击者可能构建一批 hash code 一致的数据,使得查询性能降低到 O(n)),JDK 8 及之后 在数据量到达阈值时会使用平衡树替代链表,使得最差情况的查询性能提升为 O(log n)。
由于不同对象可能有同个 hash code,因此对象需要实现 equals() 来比较不同的对象。这和 Python 类似。当在 HashMap 中查找某一 key 时,通过 key 的 hash code 定位到具体的 bucket,再将 bucket 中的 key 一个进行 equals() 比较,从而找到需要的 key。
扩容(rehashing)
默认的负载因子为 0.75,是实践中兼顾了时间(负载因子过小会频繁 rehashing 耗费性能)和空间(负载因子过小会导致 bucket 过多,浪费内存)的选择。
在插入一个新数据时,如果 HashMap 中数据量超过阈值(容量 × 负载因子),为了保证插入、删除、和查询时的 O(1) 性能,HashMap 需要扩容。(不扩容就不能保证每个 bucket 的数据都很少,也就不能保证 O(1) 的查询性能。)扩容时容量会翻倍,即桶的量会翻倍,意味着需要重新计算 key 落在哪个 bucket,这个过程即 rehashing。HashMap 会遍历旧的 bucket 数组,将数据挪至新的 bucket 数组中。此时这次插入的性能不是 O(1),变为 O(n)。