k8s 的高可用性分为两部分:业务 pod 的高可用;控制面的高可用。
业务 pod 的高可用可以通过平行扩展等方式实现,这里不深入讨论。
控制面的高可用
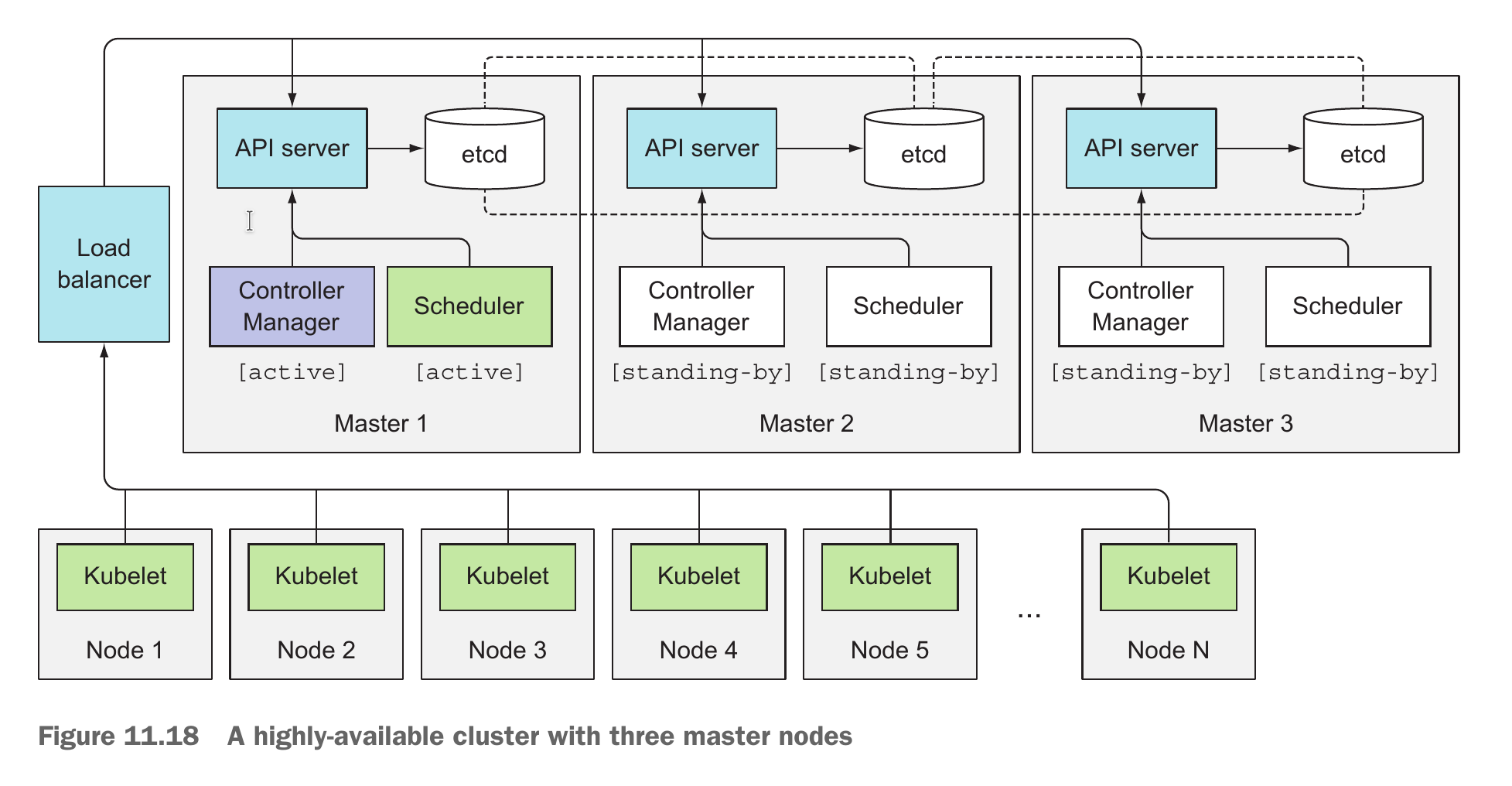
etcd 设计上就是分布式的。
kube-api-server 基本是 stateless 的,可以随便部署很多实例。一般每个 master node 上都部署一个 etcd 和 kube-api-server 实例,kube-api-server 访问本机的 etcd。kube-api-server 前应该接 load balancer,给 Controller、scheduler、kubelet 等组件访问;如果某 kube-api-server 挂掉,load balancer 可以让请求不走过去。
Controller 和 scheduler 它们设计上是应该只有一个实例在起作用的。比如 ReplicaSet 的 controller 会负责生成 pod 对象,假如有两个 controller 同时运行,可能会生成两个重复的 pod 对象。因此 k8s 采用了 leader election 的模式,部署多个实例时会选出 leader,仅有 leader 在工作,其他实例等待 leader 挂掉时再选举出新 leader 起来工作。
Leader 选举
k8s 在实现 leader 选举上非常简单。甚至同个 controller 在做 leader 选举时,它们都不需要跟彼此通信。
以 kube-scheduler 为例,在没有 leader 时,多个实例会同时向 kube-apiserver 写入一个 endpoint 实例。由于 kube-apiserver 有乐观并发控制,因此只有一个实例会写成功:

图中 control-plane.alpha.kubernetes.io/leader 中的 holderIdentity 即表示了谁是 leader(即写入成功的实例)。成为 leader 后该实例需要定期更新此 Endpoint。如果过了时间还没写,其他实例会尝试成为 leader.