速率限制(rate limiting)是后台架构中常见的策略。
场景
- 保护服务不被过度使用而影响可用性,防止级联故障(俗称「雪崩」,比如一台机器挂了后,流量压到其他机器导致更多机器被压垮),防止资源耗尽
- API 服务对使用方做配额控制
- 使用付费功能时,使用方避免费用超额而进行速率限制
策略
- 应 整体地审视 服务调用链条中的速率限制策略,如:
- 底层服务没有速率控制功能时,调用此服务的服务应该对其前端做好限制
- 客户端也应该预留设计,比如收到服务端回包表示已限流时,应该采取 指数退避 ,或者等待到某一时间点再重试
- 服务对其调用方进行限流时,应该告知调用方,比如通过 HTTP 429(too many request)等方式
- 如果用于实现速率限制策略的工具或基础架构本身失败或无法访问,则服务应该启动「应急开启」功能并尝试处理所有请求。不能因为限流功能故障而导致服务完全不可用
- 调用方如果有基于时间表的请求(比如每小时正点请求一次),应该增加额外的随机时间及应用指数退避,避免集中到同一时间请求服务端
算法
常见的有:令牌桶、漏斗、固定窗口、滑动窗口。令牌桶 是相对适合流量突增情况的。

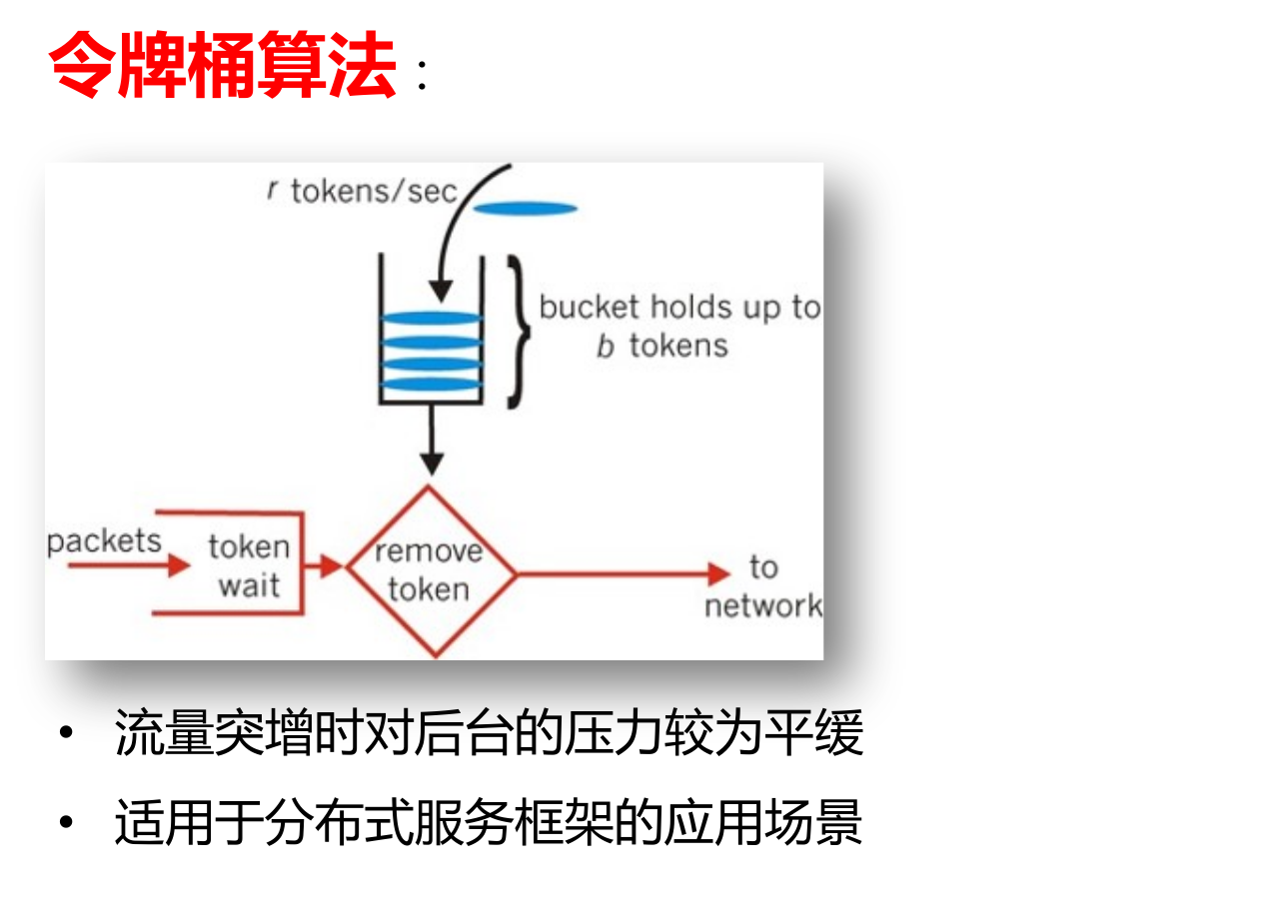
架构设计
针对单个调用方节点 / 被调用方节点,有固定的配额
比如服务 A 调用服务 B,限制是:
- 服务 A 的单个节点 只能调用固定的次数;或者
- 服务 B 的单个节点只能被调用固定的次数
这种情况比较好设计,不管是在内存中维护配额、还是用外部存储(比如 Redis 来维护配额),都是非常简单的,仅需要计数并在限额达到时限制调用 / 被调用即可。
分布式系统中的速率限制
比如在多节点的环境中,服务 A 调用服务 B,要求服务 B 的全部节点在一段时间内只能被 A 调用 10k 次。问题的复杂点在于,A 跟 B 都是多节点的。
速率限制可以做在调用方(A),也可以做在服务方(B);方法是类似的,但有时你无法控制调用方的实现。下面的分析以服务方为例。
一个常用的做法是,通过一个集中式的 data store 来维护配额信息。服务收到请求时,向 data store 申请额度,如果还有额度就可以提供服务,否则就拒绝。实现过程要注意多个服务同时申请配额时带来的 竞争状态(race condition)。一般 get-then-set 容易出现这种问题,换成 set-then-get 是比较好的,通过 set 过程的原子操作来保证该节点申请到了配额。使用 Redis 时可以用其 Lua 脚本,即可以揉入计算逻辑(比如令牌桶的计算),也可以保证执行过程原子化。
集中式 data store 的问题在于:
- 查询配额过程 会增加延迟。优化方法是,可以批量申请配额,在服务节点本地做配额是否足够的判断,这样不用每次都查询 data store
- Data store 故障时影响限流功能。服务的实现中应该做容灾,在 data store 故障时放行所有请求