Redis 的数据类型。
string
功能:
- 普通操作:
SETGET - 带过期时间:
SET key value [EX seconds],SETEX - 不存在则设置:
SETNX - 如果值是整数,可以
INCRDECR - 可以做 bitmap 功能
原理:
- 内存分配:预留内存(capacity > length);不够用时,1MB 内翻倍增长,1MB 外每次加 1MB(来自书《Redis 深度历险》,未找到官方文档来源)
list
List 是链表不是数组。插入删除 O(1),查找 O(n)。
可以实现 队列和栈。很多任务队列会使用 Redis list 作为存储。如果用来实现「生产者消费者」模型,可以用 Redis 提供的 blocking 命令,比如 BLPOP(blocking list pop),在 list 没有元素可 pop 时会 blocking,从而避免了轮询带来的开销。
底层结构:快速链表(quicklist)。原理是数据量少时连续存储,数据量大时分开。待深入。
为何 string 有 INCR,hash 有 HINCRBY,zset 有 ZINCRBY,但却没有针对 list 元素的 INCR 命令?
因为列表的查找是 O(n),而其他几个数据结构的查找是 O(1)。如果为了做个简单如自增的操作而去遍历列表元素,是不太划算的,所以 Redis 没有支持列表元素的 INCR。
hash
hash 结构类似于 Java 的 HashMap。但 key 及 value 只能是 string。文档有 命令列表。
> HSET books java "think in java"
> HSET books python "fluent python"
> HGETALL books
1) "java"
2) "think in java"
3) "python"
4) "fluent python"内部结构也是「数组 + 链表」:
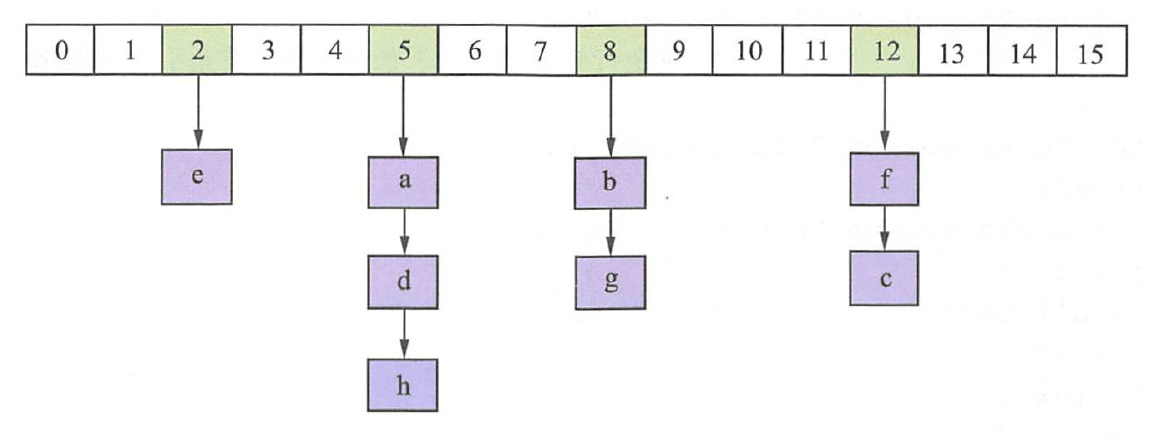
Rehash 时,Redis 为了追求高性能,不阻塞服务,会使用 渐进式 rehash 策略,即保留新旧两个 hash 结构,慢慢一次次把旧 hash 数据挪到新 hash。
set
跟 hash 类似,只是没有值。
zset
zset 是有序集合,是 Redis 特色。它类似 set,sorted set 中的元素是无序且唯一的。但是它的每个元素有一个关联的 score,这个 score 用来排序。score 相同时,将 key 按字典排序。
Sorted set 在内存中就是有序的,并不是请求过来再排序。底层的数据结构是 skip list 结合 hash table。
插入的时间复杂度是 O(log n),查询是 O(1)(未证实)。
Sorted set 支持按 score 范围查找:ZRANGEBYSCORE hackers -inf 1950 表示在查找 hackers 中分数为为 [-inf, 1950] 的元素。也可以按范围删除,通过 ZREMRANGEBYSCORE(z remove range by score)。还可以查某一元素的排名,通过 ZRANK。
Sorted set 通常被用于实现 排行榜。
bitmap
Redis 的 bitmap 就是将对 string 的操作变成对位的操作。比如 "h" 的 ASCII 码是 01101000:
> SET mymap h
OK
> GETBIT mymap 0
0
> GETBIT mymap 1
1除了 GETBIT SETBIT,Redis 还提供了 BITCOUNT 来数有几位 1,通过 BITPOS 来查指定范围第一个 0 或第一个 1。
Redis 还提供了 BITFIELD,不深入研究,它的 用意 是:
The motivation … is that the ability to store many small integers as a single large bitmap … is extremely memory efficient, and opens new use cases … especially in the field of real time analytics.
HyperLogLog
HyperLogLog 是一种概率论数据结构。针对大量数据去重统计的场景,比如 UV(unique visitor)。假如一个页面有一千万 UV,为了去重而去使用 set 是不经济的做法,会消耗非常多的内存。但是 HyperLogLog 可以避免这种问题,它最多占 12kB 内存,数据不多时甚至更少。但它不保证完全精确的统计,但误差也在 1% 以内。
命令 仅有三个:PFADD PFCOUNT PFMERGE。PF 是发明这种数据结构的教授 Philippe Flajolet 名字缩写。