Unicode 是目前处理多语言字符的标准方式。有几个概念需要理解:
Code Point
中文叫「码位」,表示一个字符在一个字符集中唯一的位置,比如 A 在 Unicode 字符集中位于 0041 的位置,所以它的 code point 是 U+0041;ñ 00F1 的位置,它的 code point 是 U+00F1。
Plane
Unicode 的全部字符,分为 17 个 plane(字符平面)存放,plane 类似于一级分类。每个 plane 中包含 0000-FFFF 一共 65536 个 code point。常用的是 Plane 0,Basic Multiligual Plane (BMP)。比如 ñ 就处在 BMP 中,它的 code point 是 U+00F1;𐀀 处在 Plane 1 中,它的 code point 是 U+10001。
Blocks
每个 plane 又分为多个 blocks,类似于二级分类。比如 BMP 中有 Basic Latin (0000-007F),这个 block 中存放 ASCII 里的全部字符;有 CJK Unified Ideographs (4E00-9FFF),存放主要的中文和日文字符。
把上面几个概念串起来,就是这幅图:
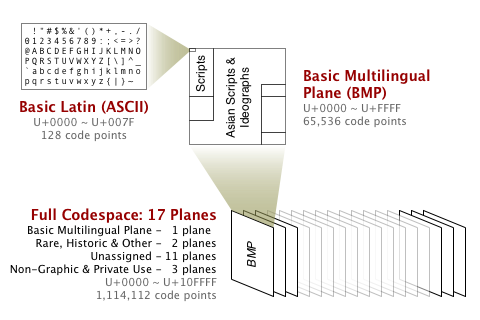
Unicode 像一本字典,每一页纸是一个 plane,每一页里面又分了很多块。Code point 是唯一找到一个字的方法,类似地址。
Encodings
Code point 只是 Unicode 字典中的地址,但是计算机间交换数据,并不以这个地址为准,而是发明了编码(encoding)系统,比如 ASCII、GBK、UTF-8 等。编码系统做的是,把一个字符(也就是它的 code point)跟一个二进制表示关联起来,可以互相转换,比如:
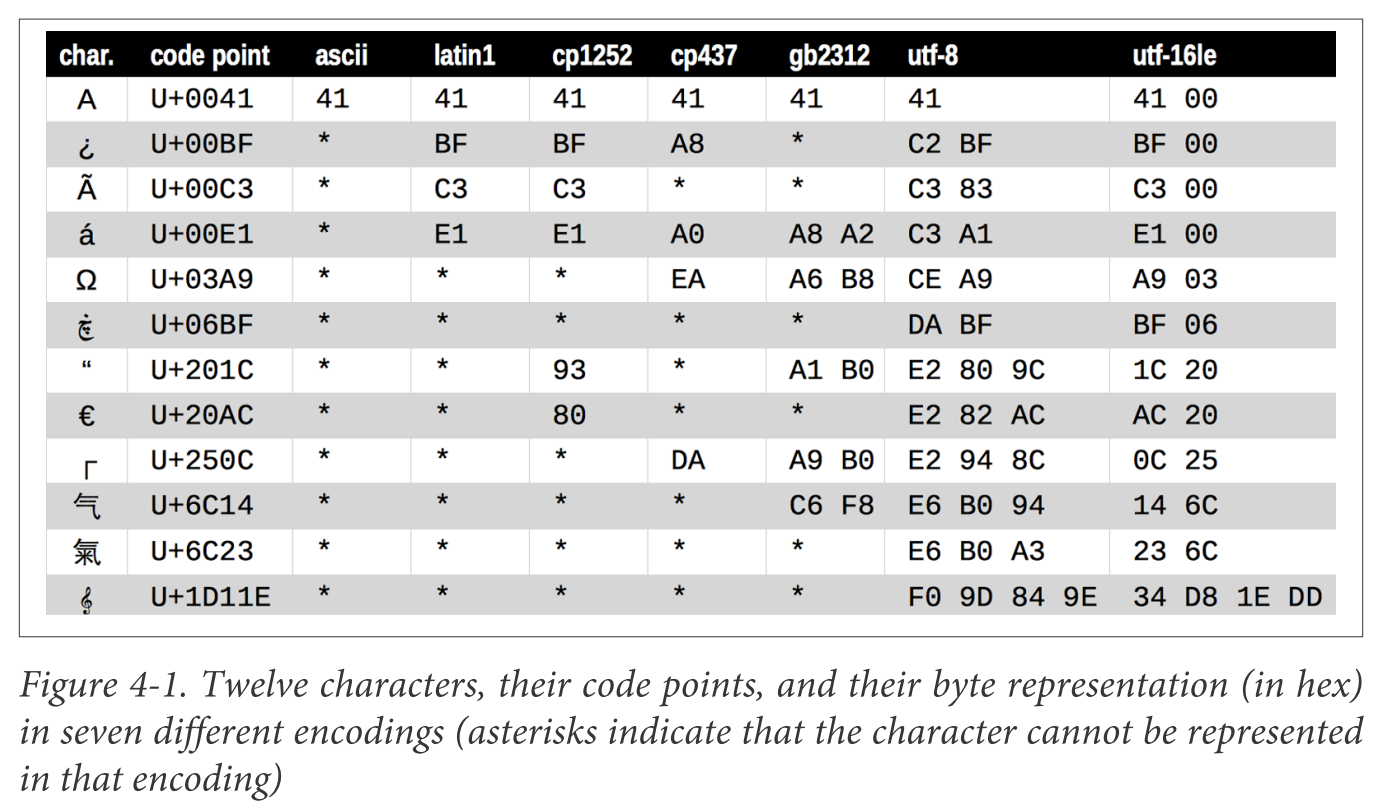
比如机器 A,想向机器 B 传输一段 "Hello World",它必须跟 B 约定好用某一种编码格式对这个字符串做编码,然后再将这串数据,编码成相应的二进制数据。如果用 ASCII 编码,最终传过去的数据,用十六进制表示就是 48656C6C6F20576F726C64。
你可能会觉得,为啥不直接用 code point 的值当作编码后的结果,进行传输。这就必须回去翻翻历史。一开始美国人发明计算机,他们觉得用 ASCII 编码就够表示所有英文字符了。但是一旦要跟中国人通信,ASCII 表达不了中文,于是中国人又搞了个 GBK 编码来表示中文字符。后来大家觉得有必要搞一套 Unicode 来把所有语言的字符包起来,避免混乱,于是 Unicode 出现了,相关的编码格式 UTF-8、UTF-16 出现了。另外,编码格式在设计时还会考虑到一些性能因素,比如现在最主流的编码格式 UTF-8。
UTF-8 是个变长的编码格式,观察这几个字符的 UTF-8 编码:
| Charater | UTF-8 |
|---|---|
| A | 0x41 |
| ñ | 0xC3B1 |
| 中 | 0xE4B8AD |
可以看到,对于不同的字符,UTF-8 编码出来的长度并不是固定的,比如中文字符编码出来会占 3 个字节。因为互联网中传输的大多数是 ASCII 字符。因此 ASCII 字符在 UTF-8 中只需要 1 个字节就可以表示。这是另外一种意义上的「压缩算法」。
一些编程语言在设计之初,Unicode 规范还没有成形或者成为主流,因此他们在字符串、字符处理上的设计,可能不是最合理的。比如 Python 2 的默认编码类型为 ascii 而不是 utf8,导致了很多新手头疼的编码问题。Java 的 char 使用 16 字节长度,只能存一个 UTF-16 能表达的字符,不知道是不是有意设计。你应该了解你的编程语言有无 Unicode 支持,以何种方式支持。
查询一个 Unicode 字符的信息:
参考: