InnoDB 的索引实现。
索引被用来加速数据查询。索引所使用的 B+ 树,在 Database: Index 中提及。
主键索引和非主键索引
区别:
- 主键索引中,索引的值和关联的行存储在一起,也被称为 聚簇索引(clustered index)
- 非主键索引的叶子节点存的是主键的值,也被称为 二级索引(secondary index)。查询时需要多扫描一颗索引树
《高性能 MySQL》中的图片:

掘金的这篇 文章 总结得非常好:
聚簇索引与非聚簇索引的特点: 聚簇索引有些优点: 聚簇索引有些缺点:展开详情
覆盖索引
当查询时仅需要索引中的数据(比如 ID),MySQL 查完索引就可以给返回,不需要查数据行。这意味着 为高频查询建立联合索引是值得的(比如查 ID 和名字)(如何衡量?)。
最左前缀原则
联合索引 (a, b) 中,在 B+ 树中索引项是按定义的字段顺序排序的。比如下面,数据先按姓名排序,再按年龄排序:
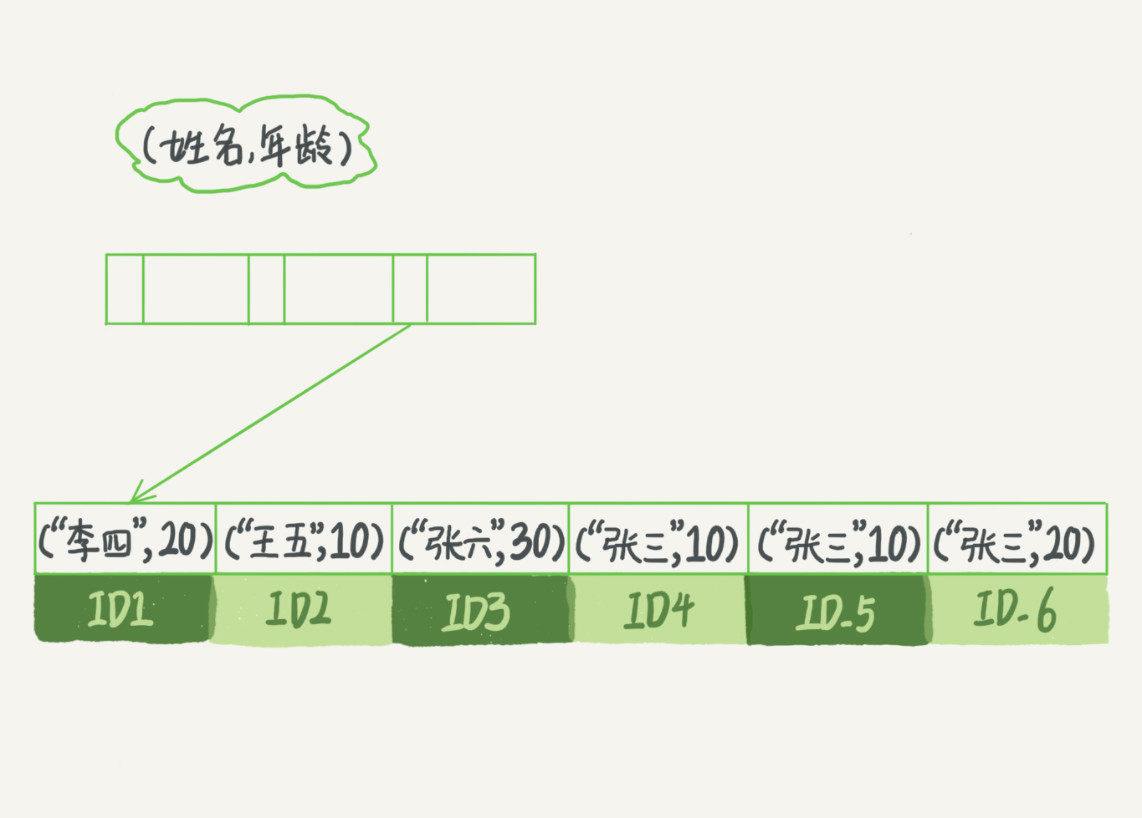
这意味着,只查姓名时也可以利用这个联合索引。但是查年龄时不行。即是说,查 (a) 或者 (a, b) 时也可以利用到联合索引 (a, b, c) 。
如果你有多个查询场景,尽量使它们可以用同一个联合索引。
模糊查询和范围查询都会导致联合索引上该查询列之后的列失效。比如:
SELECT * FROM t WHERE a LIKE 'test%' AND b='luck'因为 a 使用了模糊查询,因此即使有联合索引 (a, b),也只能利用到 a 无法用 b。
前缀索引
对字符串列做索引时,有时候完整的索引太占用空间。可以选择该列的前几个字符做索引。比如 key(email(4))。这样减少了索引的空间,但是增加了回表(即回到主键索引 B+ 树)的次数。
前缀索引会引起覆盖索引失效,因为前缀索引的字符串不完整。