- Note
- 这里的内容大多数来自 Designing Data-intensive Applications 的第三章。
目前绝大多数 RDBMS 的索引是用 B 树(B-Tree)及其增强版 B+ 树(B+Tree)实现的,比如 InnoDB 使用的是 B+ 树。
B 树 / B+ 树为了使其适用于磁盘存储,它将数据分成了 固定大小的页(多数是 4KB),每次读写都操作一个页,跟操作系统读写硬盘类似。
B 树
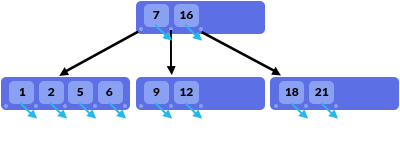
B 树长得跟图中类似。每一个蓝色块表示一个页。对于非叶子页,页定义了一批 区间(如 , 等)、边界值(如 7,16 等)、区间中数据所在的 子页的引用,以及各值的 data pointer(图中蓝色箭头表示,比如值所对应的数据行所在的文件位置)。
一旦数据在父页出现,就不会出现在子页。比如第一层的 7 并没有出现在下一层中。
对于叶子页,它并没有子页,只有值本身(比如 9、12)及其 data pointer。
B+ 树
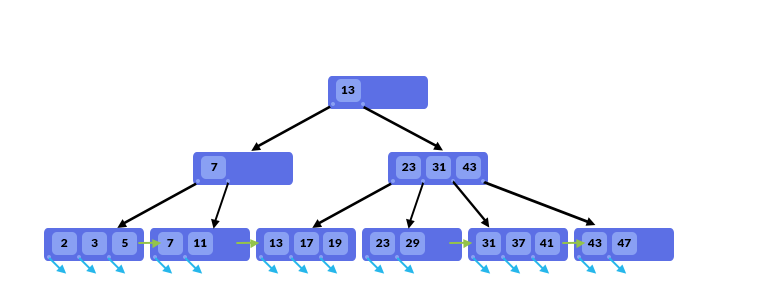
与 B 树不一样的地方在于:
- 非叶子页中的值,也会出现在子页中,比如图中的 7;同时非叶子页中不再存 data pointer,data pointer 仅存在叶子页中。意味着如果你想找 7 的 data pointer,那必须查到叶子页中
- 叶子页中,相邻的页之间会有指针连接起来(图中黄色箭头),类似链表。这对于数据库场景中做范围查询有帮助
Designing Data-intensive Applications Ch03 中的插图:
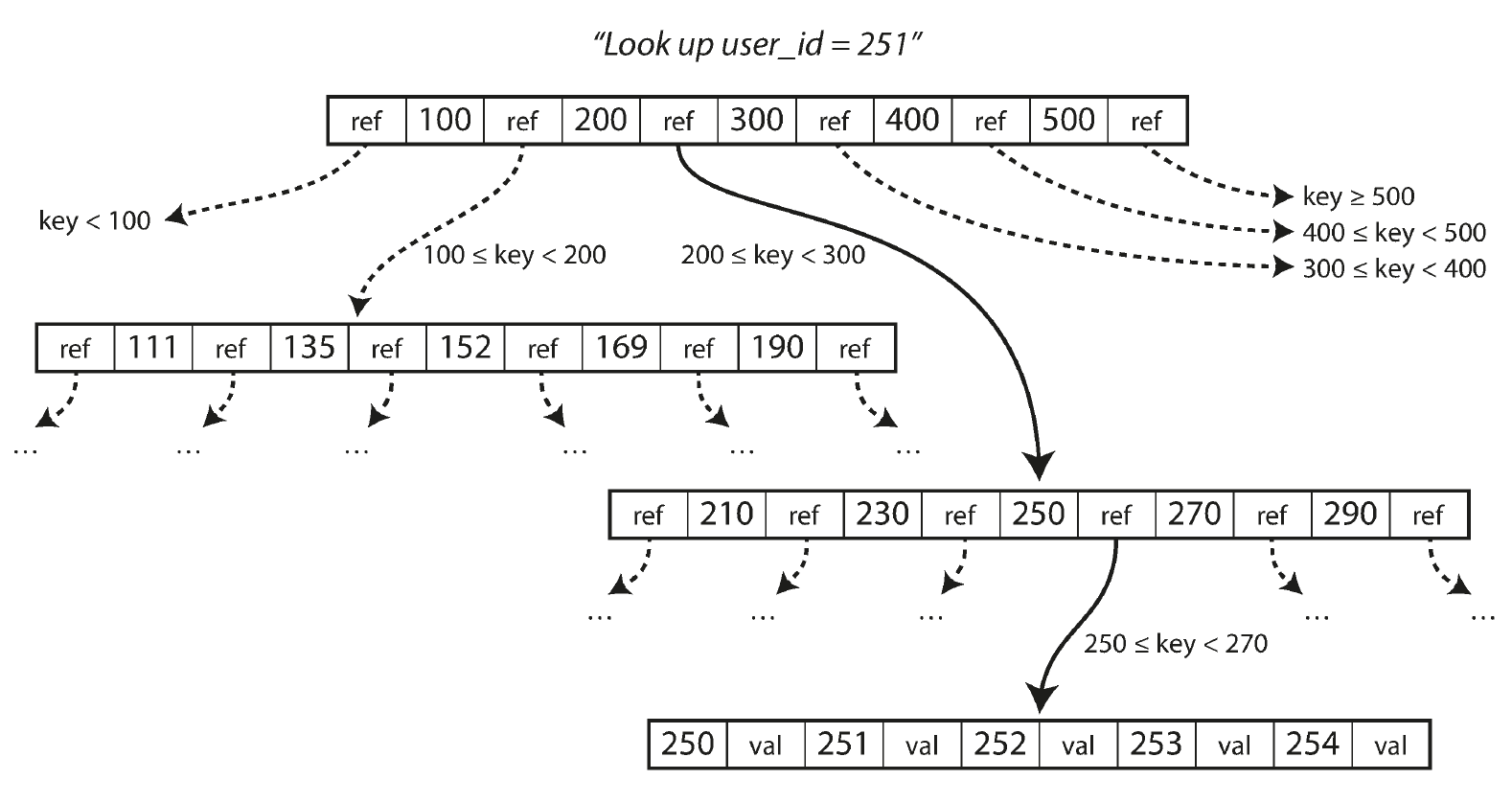
操作
无论插入删除元素,由于 B+ 树的第一点特性,它会比 B 树更容易操作:
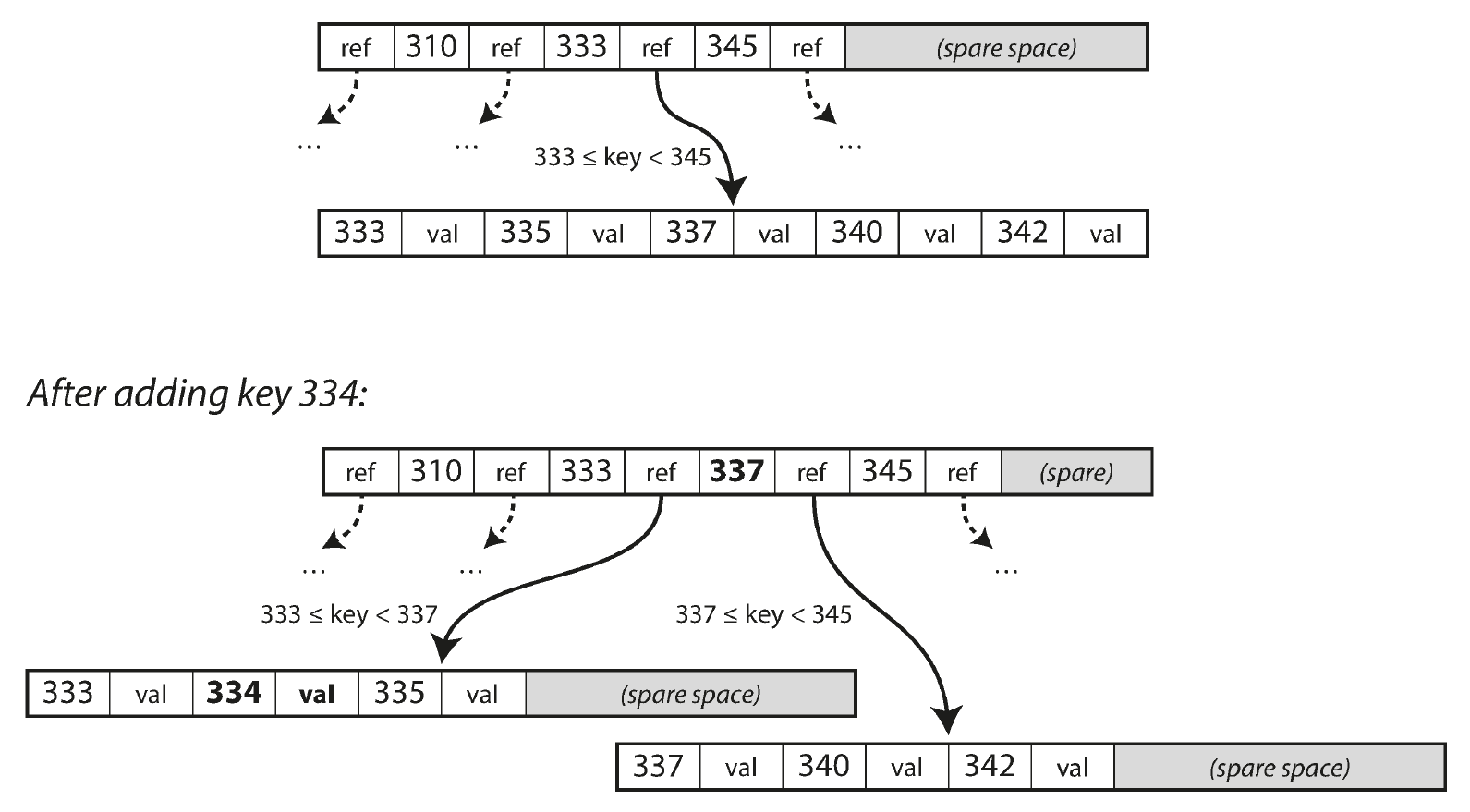
删除元素则比较复杂,暂无研究。
特性
这个算法保证了这颗树永远是平衡的。一颗有 n 个 key 的 B 树的深度是 。每个页中包含的分区数称为 分支因子(branching factor)。实践中 B 树的分支因子非常大,一个 4 层、单页 4KB 以及分支因子为 500 的树可以存储 256TB 数据。
可靠性
一般需要搭配 WAL 以避免写一半时 crash 引起的数据损坏,比如 InnoDB 的 redo log。
修改 B+ 树时需要精细的并发控制,一般使用轻量的锁。
优化
- 有些数据库(如 LMDB)使用 copy-on-write 方式,不需要维护一份 WAL
- 页中的 key 值不一定要是完整的。可以只纪录初始 key 值,后面的 key 使用偏移量来表达,这样一页可以塞进更多的 key
- 一些数据库会尝试让树的叶子页在磁盘上是连续的,使得查询大量数据时 I/O 性能更佳